
【Python数据分析案例】(十五)——超高维数据的降维(随机森林)、特征工程

网盘截屏

▶全部源码和数据,请点击“支付下载”获取!支付后无网盘链接,请联系客服QQ:3345172409或1919588043(微信同号)☺
导读
本次带来的案例是高维数据的处理,以及降维,使用随机森林降维和分类。
本次数据长这个样子,没有特征名称
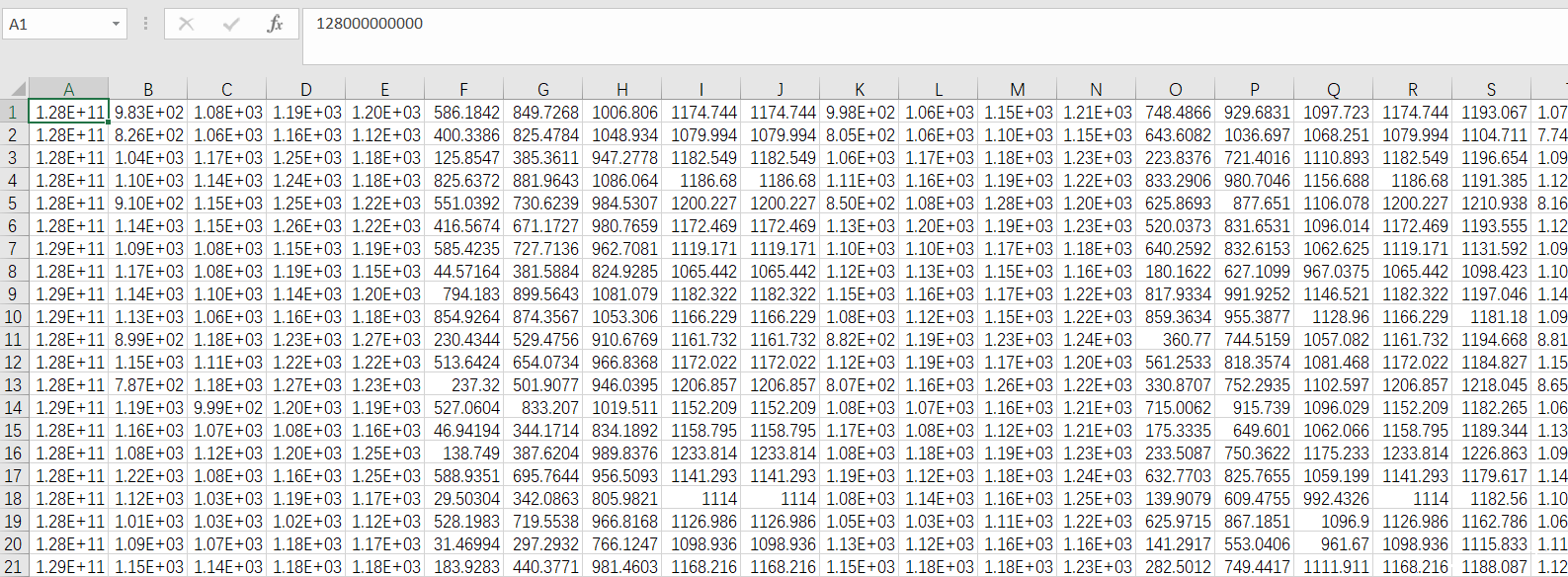
只有最后一列是0和1 ,代表响应变量y,这是一个二分类问题。其他前面都是x。
首先导入包,读取数据的时候给每个变量命个名称,从var1到var250:
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
读取数据,给训练集和测试集都命名
names=['var'+str(i+1) for i in range(250)]
data=pd.read_csv('train.csv',header=None,names=names)
data2=pd.read_csv('test.csv',header=None,names=names)
如果有一行全为空值就删除
data.dropna(how=’all’,inplace=True)
data2.dropna(how=’all’,inplace=True)
查看训练集数据
data
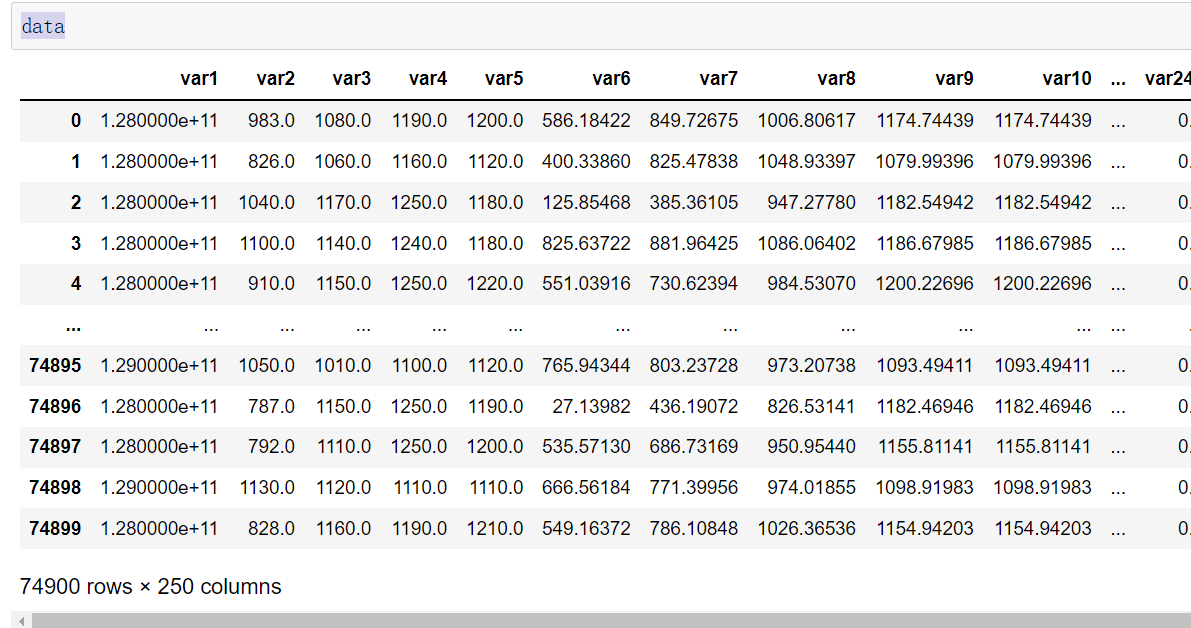
可以看到数据有74900条,250维特征,算是高维数据了。
继续清洗,降维
首先取值唯一的变量都删除,就是这一列的特征全为一样的数值的话就删除,因为值都是一样的,这个特征对于分类就没帮助
#取值唯一的变量都删除
for col in data.columns:
if len(data[col].value_counts())==1:
print(col)
data.drop(col,axis=1,inplace=True)

打印了一下删除的变量的名称。
然后将文本型的数据都删掉,平时对于文本类数据可以要处理一下,比如独热编码之类的,但是数据维度很高,直接扔了也没损失很多信息
data=data.select_dtypes(include=['float64'])
然后将缺失值过多的列删除,这里阈值是74000,就是说一个列特征的缺失值达到900条的特征就删除
data=data.dropna(thresh=74000,axis=1)
查看数据
data
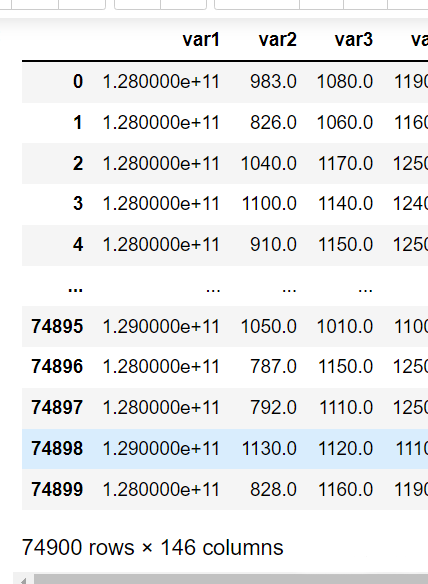
从250维度降到146,继续
观察缺失值
#观察缺失值 import missingno as msno %matplotlib inline msno.matrix(data)

可以看到缺失值不算很多了,那就直接填充,取上一个值填充空值
data.fillna(method='pad',axis=1,inplace=True)
然后将上面挑选出来的特征给测试集也做一些同样的处理
data2=data2[data.columns[:-1]] data2=data2.fillna(method='pad',axis=1)
下面开始用机器学习的方法降维。
开始机器学习
划分X和y
y=data.iloc[:,-1] X=data.iloc[:,:-1] X.shape,y.shape

145个特征
划分训练验证集
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=0)
数据归一化
from sklearn.preprocessing import MinMaxScaler scaler =MinMaxScaler() scaler.fit(X_train) X_train_s = scaler.transform(X_train) X_test_s = scaler.transform(X_test) #x=scaler.transform(data2) #row_id2=data2.iloc[:,0] X2=data2.iloc[:,:] scaler =MinMaxScaler() X3=np.vstack((X,X2)) scaler.fit(X3) X_s = scaler.transform(X) X2_s = scaler.transform(X2)
先用逻辑回归试一试分类效果
#逻辑回归 from sklearn.linear_model import LogisticRegression model = LogisticRegression(C=1e10,max_iter=1e6) model.fit(X_train_s, y_train) model.score(X_test_s, y_test)
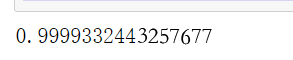
准确率很高
然后使用随机森林分类
#随机森林 from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=123) model.fit(X_train_s, y_train) model.score(X_test_s, y_test)
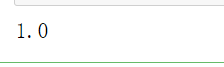
准确率直接100%了。。。
然后对测试集集预测,然后保存
pred = model.predict(X2_s)
df = pd.DataFrame(columns=['target'])
#df['row_id']=row_id2
df['target']=pred
df.to_csv('predict_result.csv',header=False,index=False)
下面我们在不降低准确率的情况下对数据进行筛选,首先画出变量的重要性排序图
model.feature_importances_
sorted_index = model.feature_importances_.argsort()
plt.barh(range(X_train.shape[1]), model.feature_importances_[sorted_index])
plt.yticks(np.arange(X_train.shape[1]), X_train.columns[sorted_index])
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('Random Forest')
plt.tight_layout()
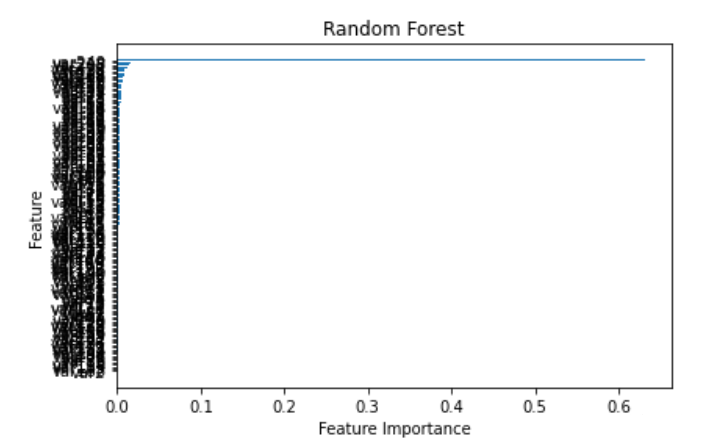
由于特征太多了,直接密密麻麻看不清…..大体上我们看的出来是第一个特征对分类的帮助很大,其他特征的重要性则没那么高。
我们查看一些排序后的变量名称和各种的重要性
var_names=X_train.columns[sorted_index][::-1] var_weight=model.feature_importances_[sorted_index][::-1] #imf_weight[0]=1 var_names,var_weight

可以看到最重要的变量是var249.
我们可以设置一个阈值,变量重要性小于这个阈值就不要这个变量
重要变量=var_names[var_weight>0.002] 重要变量的系数=var_weight[:len(重要变量)]
然后筛选出来的变量应用到训练集和测试集上
X_train=X_train.loc[:,重要变量] X_test=X_test.loc[:,重要变量]
然后数据标准化,再进行随机森林分类
scaler2 =MinMaxScaler() scaler2.fit(X_train) X_train_s = scaler2.transform(X_train) X_test_s = scaler2.transform(X_test) #随机森林 from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=123) model.fit(X_train_s, y_train) model.score(X_test_s, y_test)
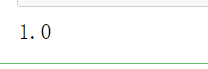
还是100%,说明我们筛选掉了一些变量,但是模型的准确率没有下降。
然后将筛选出来的变量去保存
model.feature_importances_
sorted_index = model.feature_importances_.argsort()
var_names=X_train.columns[sorted_index][::-1]
var_weight=model.feature_importances_[sorted_index][::-1]
var_names,var_weight
var=pd.DataFrame()
var['重要变量']=var_names
var['重要变量的重要性程度']=var_weight
var.to_csv('筛选变量.csv',index=False,encoding='gbk')
df=data[var_names].to_csv('训练集筛选的X变量.csv',index=False)
df2=data2[var_names].to_csv('测试集筛选的X变量.csv',index=False)
这样就达到了降维的目的。
当然也可以使用sklearn里面的SelectFromModel可以便捷一点。
from sklearn.feature_selection import SelectFromModel model = RandomForestClassifier(n_estimators=5000, max_features=int(np.sqrt(X.shape[-1])), random_state=0) model.fit(X,y) selection =SelectFromModel(model,threshold=0.002,prefit=True) select_X=selection.transform(X) select_X.shape
这样可以直接把筛选出来的X应用到训练集上,还可以运用到测试集上,也可以很方便的查看筛选出来的变量
print(selection.get_support()) print(selection.get_support(True)) [columns[i] for i in selection.get_support(True)]












