
【Python数据分析案例】(十四)——天气K均值聚类分析

网盘截屏
▶全部源码和数据,请点击“支付下载”获取!支付后无网盘链接,请联系客服QQ:3345172409或1919588043(微信同号)☺
案例背景
聚类常用的算法肯定是K均值聚类了,本次案例采用陕西的十个地区的天气数据,构建特征,进行聚类分析。
首先数据都装在‘天气数据’这个文件夹里面,如图:

打开其中一个excel,长这个样子
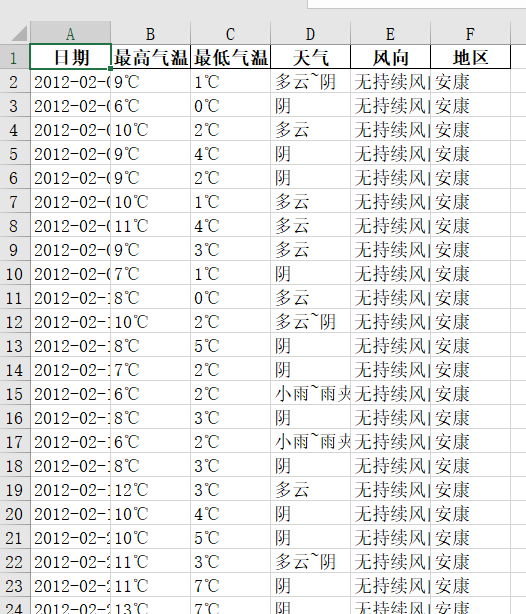
下面开始数据处理
数据预处理
导入包
import os
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
import datetime as dt
import re
#from sklearn.preprocessing import MinMaxScaler
%matplotlib inline
pd.options.display.float_format = '{:,.4f}'.format
np.set_printoptions(precision=4)
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
获取文件和地区名称
file_name=os.listdir(f'./天气数据') print(file_name) region_name=[i[:2] for i in file_name] region_name

定义一些函数,用来处理数据
def date_transform(x) :
a= x.split(' ')[0]
a = pd.to_datetime(a, format='%Y-%m-%d')
return a
def C_check(C):
a=C.split('℃')
return int(a[0])
def tianqi_check1(txt):
if '转' in txt:
a=re.findall('\w{1,5}转',txt)
a=a[0].split('转')
a=a[0]
elif '~' in txt:
a=re.findall('\w{1,5}~',txt)
a=a[0].split('~')
a=a[0]
else:
a=txt
return a
def tianqi_check2(txt):
if '到' in txt:
a=re.findall('到\w{1,5}',txt)
a=a[0].split('到')
a=a[1]
else:
a=txt
return a
df_最高气温=pd.DataFrame()
df_最低气温=pd.DataFrame()
df_天气=pd.DataFrame()
dic_天气={'晴':0,'晴到多云':0.5,'晴间多云':0.5,'局部多云':0.5,'多云':1,'少云':1.5,'阴':2,'阴天':2,'雾':2.5,'霾':2.5,'小雨':3,'雨':3,'阴到小雨':2.5,
'小到中雨':3.5,'小雨到中雨':3.5,'阵雨':3.5,'中雨':4,'小雨到大雨':4,'雷阵雨':4,'雷雨':4,'中到大雨':4.5,'大雨':5,'大到暴雨':5.5,
'暴雨':6,'暴风雨':6.5,'小雪':7,'雨夹雪 ':7,'雪':7,'中雪':8,'大雪':9,'浮尘':2.5,'扬沙':2.5,'风':2.5}
开始读取和处理
for i,f in enumerate(file_name):
#print(i)
file_path = f’./天气数据/{f}’
data=pd.read_excel(file_path,usecols=[‘日期’,’最高气温’,’最低气温’,’天气’])
data[‘日期’]=data[‘日期’].apply(date_transform)
data[‘最高气温’]=data[‘最高气温’].apply(C_check)
data[‘最低气温’]=data[‘最低气温’].apply(C_check)
data[‘天气’]=data[‘天气’].astype(str).apply(tianqi_check1)
data[‘天气’]=data[‘天气’].astype(str).apply(tianqi_check2)
data.loc[:,’天气’]=data[‘天气’].map(dic_天气)
data[‘天气’].fillna(data[‘天气’].mean)
data=data.set_index(‘日期’).resample(‘M’).mean()
#print(len(data))
df_最高气温[region_name[i]]=data[‘最高气温’]
df_最低气温[region_name[i]]=data[‘最低气温’]
df_天气[region_name[i]]=data[‘天气’]
最后是形成了三个数据框,最高温和最低温,还有天气情况(比如下雨还是晴天等等),天气情况我用map进行了映射,都变成了数值型变量。
描述性统计
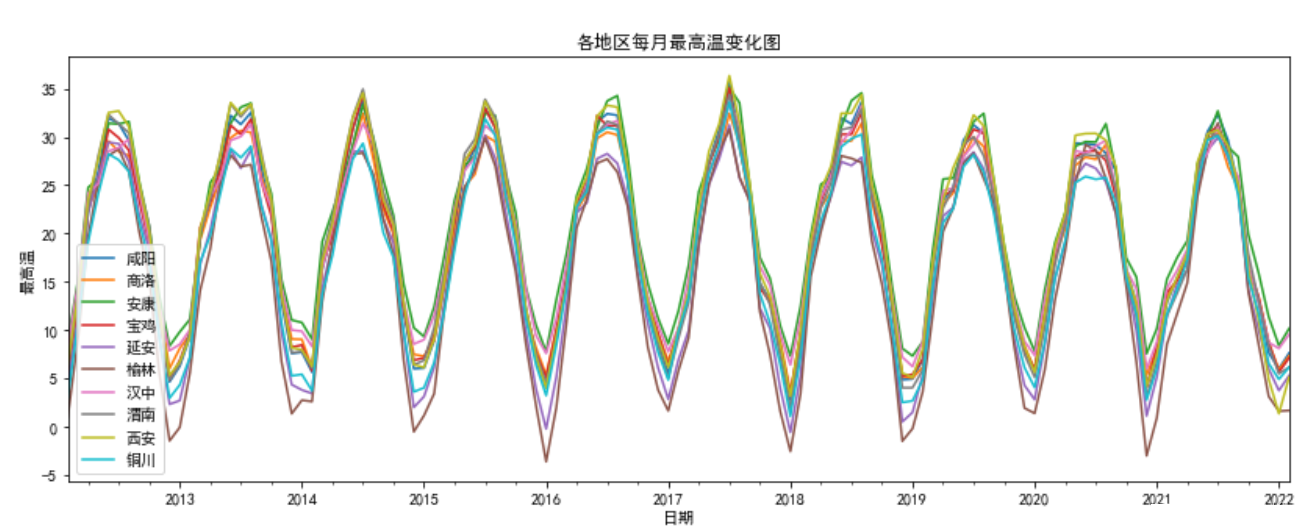
df_最高气温.plot(title='各地区每月最高温变化图',figsize=(14,5),xlabel='日期',ylabel='最高温')
df_最低气温.plot(title='各地区每月最低温变化图',figsize=(14,5),xlabel='日期',ylabel='最低温')

df_天气.plot(title='各地区每月天气变化图',figsize=(14,5),xlabel='日期',ylabel='天气')
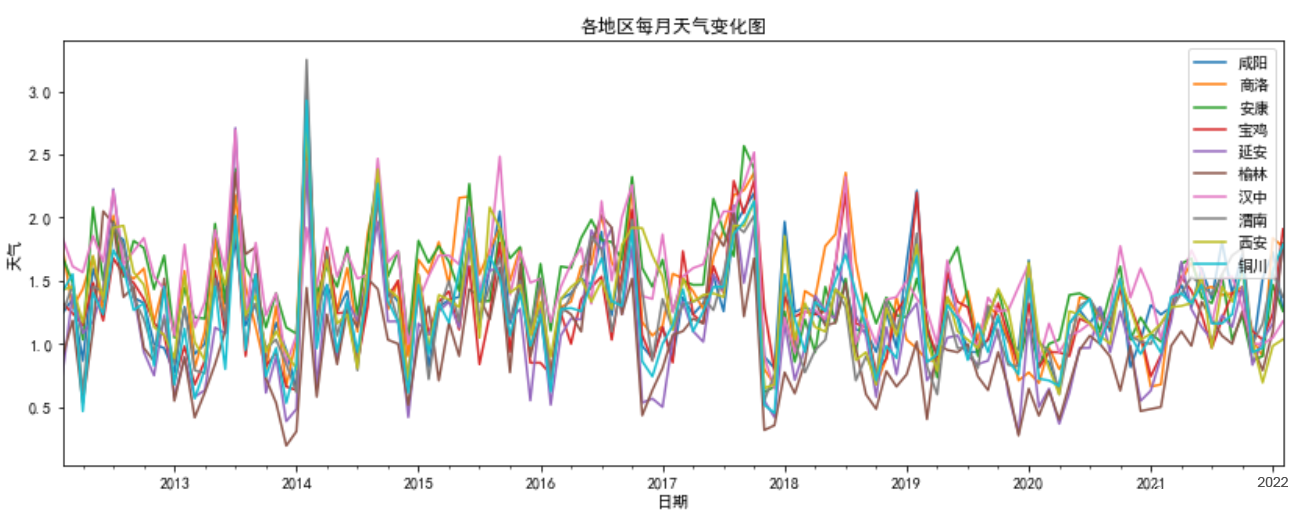
都具有很明显的周期性,天气因为是自己映射的数值型数据,所以有点杂乱。
然后画出最高温的箱线图:
column = df_最高气温.columns.tolist() # 列表头
fig = plt.figure(figsize=(20, 8), dpi=128) # 指定绘图对象宽度和高度
for i in range(len(column)):
plt.subplot(2,5, i + 1) # 2行5列子图
sns.boxplot(data=df_最高气温[column[i]], orient="v",width=0.5) # 箱式图
plt.ylabel(column[i], fontsize=16)
plt.title(f'{region_name[i]}每月最高温箱线图',fontsize=16)
plt.tight_layout()
plt.show()
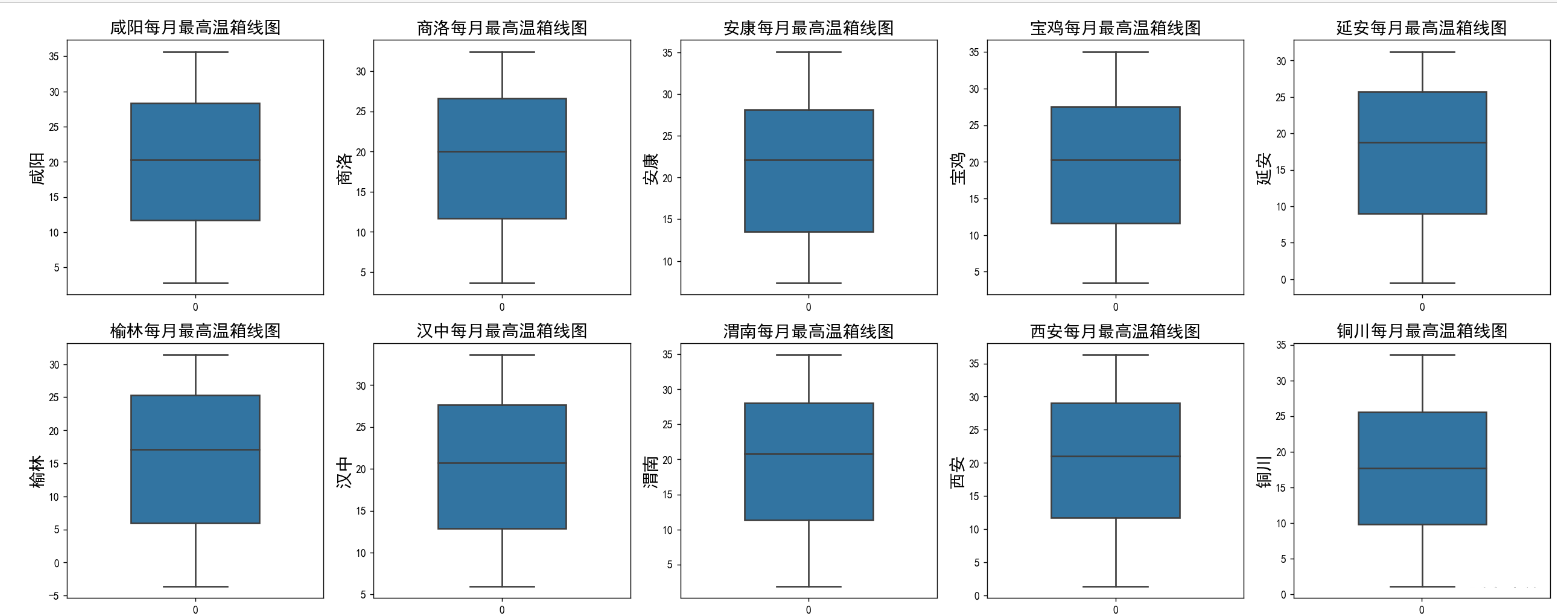
最低温和天气也是一样画,数据框名称改一下就行。
下面画出最低温的核密度图(同理最高温和天气也是一样的)
fig = plt.figure(figsize=(20, 8), dpi=128) # 指定绘图对象宽度和高度
for i in range(len(column)):
plt.subplot(2,5, i + 1) # 2行5列子图
ax = sns.kdeplot(data=df_最低气温[column[i]],color=’blue’,shade= True)
plt.ylabel(column[i], fontsize=16)
plt.title(f'{region_name[i]}每月最低温核密度图’,fontsize=16)
plt.tight_layout()
plt.show()

画出天气的相关性热力图
fig = plt.figure(figsize=(8, 8), dpi=128) corr= sns.heatmap(df_天气[column].corr(),annot=True,square=True)
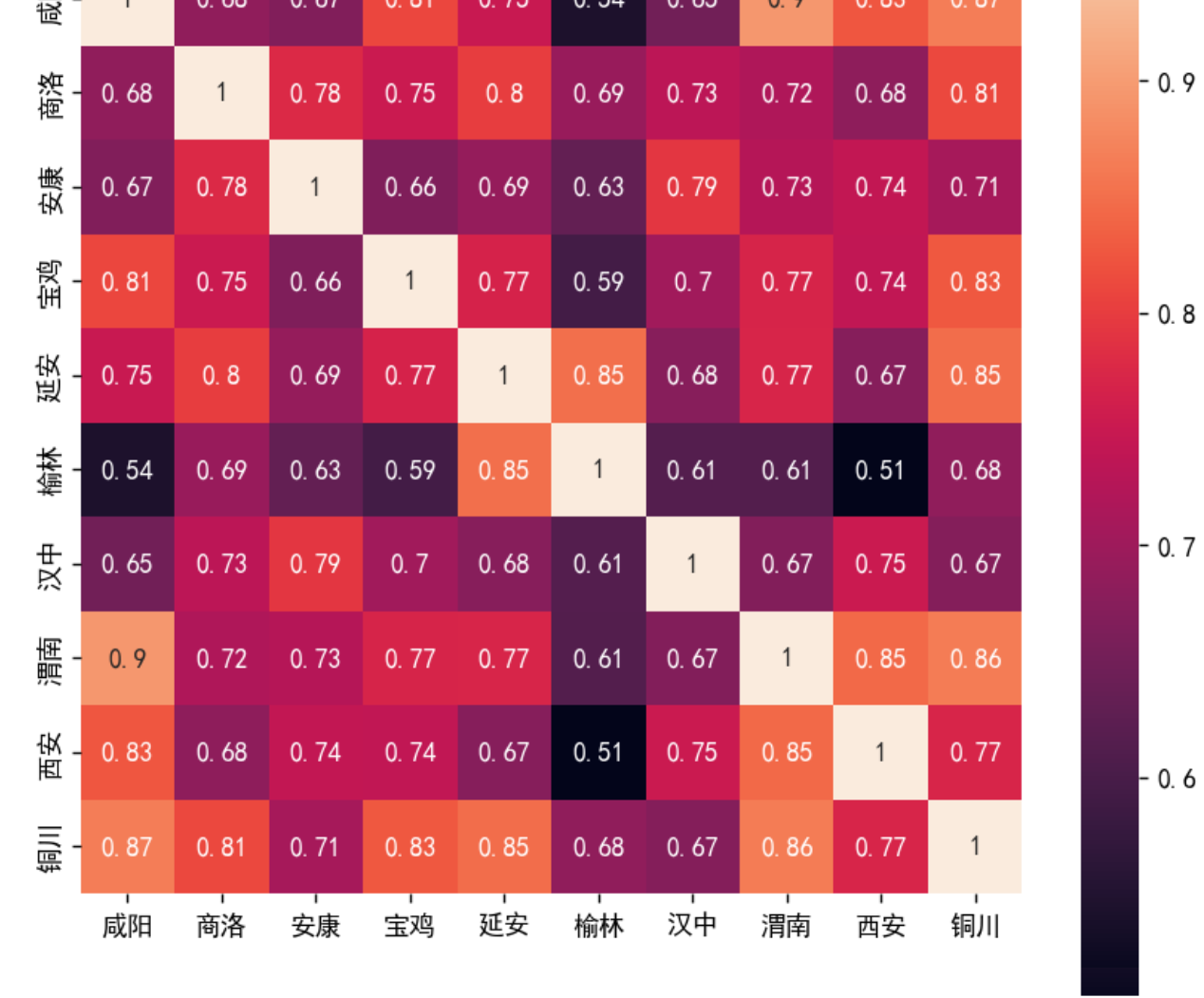
最高温和最低温也是一样,改一下数据框名称就行。可以看到哪些地区的天气相关性高
K均值聚类
因为本次构建了三个特征,可以进行三次K均值聚类,我们可以比较一下聚类的结果,首先使用最高温进行聚类:
最高温的聚类
from sklearn.cluster import KMeans kmeans_model = KMeans(n_clusters=3, random_state=123, n_init=20) kmeans_model.fit(df_最高气温.T) kmeans_model.inertia_ #组内平方和 # kmeans_cc=kmeans_model.cluster_centers_ # 聚类中心 # kmeans_cc kmeans_labels = kmeans_model.labels_ # 样本的类别标签 kmeans_labels pd.Series(kmeans_labels).value_counts() # 统计不同类别样本的数目

映射一下类别的数值
dic_rusult={}
for i in range(10):
dic_rusult[df_最高气温.T.index[i]]=kmeans_labels[i]
dic_rusult

统计一下,打印结果
第一类地区=[]
第二类地区=[]
第三类地区=[]
for k,v in dic_rusult.items():
if v==0:
第一类地区.append(k)
elif v==1:
第二类地区.append(k)
elif v==2:
第三类地区.append(k)
print(f'从最高气温来看的聚类的结果,将地区分为三个地区,\n第一个地区为:{第一类地区},\n第二个地区为:{第二类地区},\n第三个地区为:{第三类地区}')

可以去地图上看看,聚类的结果还是很有道理的,聚类出来的地区都是挨得很近的地方。
最低温度K均值聚类
kmeans_model = KMeans(n_clusters=3, random_state=123, n_init=20)
kmeans_model.fit(df_最低气温.T)
kmeans_labels = kmeans_model.labels_ # 样本的类别标签
kmeans_labels
pd.Series(kmeans_labels).value_counts() # 统计不同类别样本的数目
dic_rusult2={}
for i in range(10):
dic_rusult2[df_最低气温.T.index[i]]=kmeans_labels[i]
dic_rusult2
第一类地区=[]
第二类地区=[]
第三类地区=[]
for k,v in dic_rusult2.items():
if v==2:
第一类地区.append(k)
elif v==1:
第二类地区.append(k)
elif v==0:
第三类地区.append(k)
print(f'从最低气温来看的聚类的结果,将地区分为三个地区,\n第一个地区为:{第一类地区},\n第二个地区为:{第二类地区},\n第三个地区为:{第三类地区}')

和最高温的聚类结果差不多
第一个地区对应的关中
第二个地区对应的陕北
第三个地区对应的陕南
天气K均值聚类
kmeans_model = KMeans(n_clusters=3, random_state=123, n_init=20)
kmeans_model.fit(df_天气.T)
kmeans_labels = kmeans_model.labels_ # 样本的类别标签
pd.Series(kmeans_labels).value_counts() # 统计不同类别样本的数目
dic_rusult3={}
for i in range(10):
dic_rusult3[df_天气.T.index[i]]=kmeans_labels[i]
dic_rusult3
第一类地区=[]
第二类地区=[]
第三类地区=[]
for k,v in dic_rusult3.items():
if v==1:
第一类地区.append(k)
elif v==2:
第二类地区.append(k)
elif v==0:
第三类地区.append(k)
print(f'从天气来看的聚类的结果,将地区分为三个地区,\n第一个地区为:{第一类地区},\n第二个地区为:{第二类地区},\n第三个地区为:{第三类地区}')
天气的效果和气温差不多。
第一个地区对应的关中
第二个地区对应的陕北
第三个地区对应的陕南
说明地理位置近的地区的天气更加相似(算法说的)












