【Python数据分析案例】(七)——海上风力发电预测(多变量循环神经网络)

网盘截屏

▶全部源码和数据,请点击“支付下载”获取!支付后无网盘链接,请联系客服QQ:3345172409或1919588043(微信同号)☺
导读
本案例适合理工科。
承接上一篇的硬核案例:【Python数据分析案例】(六)——基于深度学习的锂电池寿命预测
本次案例类似,只是进一步拓展了时间序列预测到多变量的情况。上一个案例的时间序列都是只有电池容量一个特征变量,现在采用多个变量进行神经网络模型的构建。
案例背景
海上风电是最佳很热门的工程,准确预测自然很重要。
本次简单使用一些常见的神经网络进行预测效果对比。(试试手的小案例)
数据集有很多特征,如下:

V是风速,D是风向,还有什么空气湿度balabala一堆特征,最后的一列是电功率。
代码准备
和上一篇案例差不多,都是有大量的自定义函数。
首先导入包,
import os import math import time import datetime import random as rn import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文 plt.rcParams ['axes.unicode_minus']=False #显示负号 from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler,StandardScaler from sklearn.metrics import mean_absolute_error from sklearn.metrics import mean_squared_error,r2_score import tensorflow as tf import keras from keras.models import Model, Sequential from keras.layers import GRU, Dense,Conv1D, MaxPooling1D,GlobalMaxPooling1D,Embedding,Dropout,Flatten,SimpleRNN,LSTM from keras.callbacks import EarlyStopping #from tensorflow.keras import regularizers #from keras.utils.np_utils import to_categorical from tensorflow.keras import optimizers
读取数据,由于数据量太大,我就只取了前1000条来试试水
data0=pd.read_excel('5.xlsx').iloc[:1000,:].set_index('Sequence No.').rename(columns={'y (% relative to rated power)':'y'})
data0.head()

定义随机数种子函数和评估函数
def set_my_seed(): os.environ['PYTHONHASHSEED'] = '0' np.random.seed(1) rn.seed(12345) tf.random.set_seed(123) def evaluation(y_test, y_predict): mae = mean_absolute_error(y_test, y_predict) mse = mean_squared_error(y_test, y_predict) rmse = np.sqrt(mean_squared_error(y_test, y_predict)) mape=(abs(y_predict -y_test)/ y_test).mean() r_2=r2_score(y_test, y_predict) return mae, rmse, mape,r_2 #mse
构建序列数据的测试集和训练集函数
def build_sequences(text, window_size=24): #text:list of capacity x, y = [],[] for i in range(len(text) - window_size): sequence = text[i:i+window_size] target = text[i+window_size] x.append(sequence) y.append(target) return np.array(x), np.array(y) def get_traintest(data,train_size=len(data0),window_size=24): train=data[:train_size] test=data[train_size-window_size:] X_train,y_train=build_sequences(train,window_size=window_size) X_test,y_test=build_sequences(test,window_size=window_size) return X_train,y_train[:,-1],X_test,y_test[:,-1]
构建五种模型函数,还有画损失图和画拟合图的函数。
def build_model(X_train,mode='LSTM',hidden_dim=[32,16]):
set_my_seed()
model = Sequential()
if mode=='RNN':
#RNN
model.add(SimpleRNN(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(SimpleRNN(hidden_dim[1]))
elif mode=='MLP':
model.add(Dense(hidden_dim[0],activation='relu',input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(Flatten())
model.add(Dense(hidden_dim[1],activation='relu'))
elif mode=='LSTM':
# LSTM
model.add(LSTM(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(LSTM(hidden_dim[1]))
elif mode=='GRU':
#GRU
model.add(GRU(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(GRU(hidden_dim[1]))
elif mode=='CNN':
#一维卷积
model.add(Conv1D(hidden_dim[0], kernel_size=3, padding='causal', strides=1, activation='relu', dilation_rate=1, input_shape=(X_train.shape[-2],X_train.shape[-1])))
#model.add(MaxPooling1D())
model.add(Conv1D(hidden_dim[1], kernel_size=3, padding='causal', strides=1, activation='relu', dilation_rate=2))
#model.add(MaxPooling1D())
model.add(Flatten())
model.add(Dense(1))
model.compile(optimizer='Adam', loss='mse',metrics=[tf.keras.metrics.RootMeanSquaredError(),"mape","mae"])
return model
def plot_loss(hist,imfname=''):
plt.subplots(1,4,figsize=(16,2))
for i,key in enumerate(hist.history.keys()):
n=int(str('14')+str(i+1))
plt.subplot(n)
plt.plot(hist.history[key], 'k', label=f'Training {key}')
plt.title(f'{imfname} Training {key}')
plt.xlabel('Epochs')
plt.ylabel(key)
plt.legend()
plt.tight_layout()
plt.show()
def plot_fit(y_test, y_pred):
plt.figure(figsize=(4,2))
plt.plot(y_test, color="red", label="actual")
plt.plot(y_pred, color="blue", label="predict")
plt.title(f"拟合值和真实值对比")
plt.xlabel("Time")
plt.ylabel('power')
plt.legend()
plt.show()
定义训练函数,准备两个数据框,一个装评价指标,一个装预测结果。
df_eval_all=pd.DataFrame(columns=['MAE','RMSE','MAPE','R2'])
df_preds_all=pd.DataFrame()
def train_fuc(mode='LSTM',window_size=64,batch_size=32,epochs=50,hidden_dim=[32,16],train_ratio=0.8,show_loss=True,show_fit=True):
#准备数据
data=data0.to_numpy()
#归一化
scaler = MinMaxScaler()
scaler = scaler.fit(data[:,:-1])
X=scaler.transform(data[:,:-1])
y_scaler = MinMaxScaler()
y_scaler = y_scaler.fit(data[:,-1].reshape(-1,1))
y=y_scaler.transform(data[:,-1].reshape(-1,1))
train_size=int(len(data)*train_ratio)
X_train,y_train,X_test,y_test=get_traintest(np.c_[X,y],window_size=window_size,train_size=train_size)
print(X_train.shape,y_train.shape,X_test.shape,y_test.shape)
#构建模型
s = time.time()
set_my_seed()
model=build_model(X_train=X_train,mode=mode,hidden_dim=hidden_dim)
earlystop = EarlyStopping(monitor='loss', min_delta=0, patience=5)
hist=model.fit(X_train, y_train,batch_size=batch_size,epochs=epochs,callbacks=[earlystop],verbose=0)
if show_loss:
plot_loss(hist)
#预测
y_pred = model.predict(X_test)
y_pred = y_scaler.inverse_transform(y_pred)
y_test = y_scaler.inverse_transform(y_test.reshape(-1,1))
#print(f'真实y的形状:{y_test.shape},预测y的形状:{y_pred.shape}')
if show_fit:
plot_fit(y_test, y_pred)
e=time.time()
print(f"运行时间为{round(e-s,3)}")
df_preds_all[mode]=y_pred.reshape(-1,)
s=list(evaluation(y_test, y_pred))
df_eval_all.loc[f'{mode}',:]=s
s=[round(i,3) for i in s]
print(f'{mode}的预测效果为:MAE:{s[0]},RMSE:{s[1]},MAPE:{s[2]},R2:{s[3]}')
print("=======================================运行结束==========================================")
初始化参数:
window_size=64 batch_size=32 epochs=50 hidden_dim=[32,16] train_ratio=0.8 show_fit=True show_loss=True mode='LSTM' #RNN,GRU,CNN
神经网络
上面封装了那么多自定义函数就是为了下面训练的方便,
传入参数就可以训练然后评价了。
LSTM网络
train_fuc(mode='LSTM')

可以看到清楚地打印的损失图和拟合图,然后是误差指标的计算。
若想改参数,直接在训练函数里面改就行,例如想将滑动窗口改小一点,改为16,神经元个数也改多一点,改为128和32,这样写就行:
train_fuc(mode='LSTM',window_size=16,hidden_dim=[128,32])

可以看到,拟合优度上升了一点。
可以继续调整 。
RNN预测
修改mode这个参数就行。
mode='RNN' set_my_seed() train_fuc(mode=mode,window_size=window_size,batch_size=32,epochs=epochs,hidden_dim=hidden_dim)

GRU预测
mode='GRU' set_my_seed() train_fuc(mode=mode,window_size=window_size,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)

效果很不错!
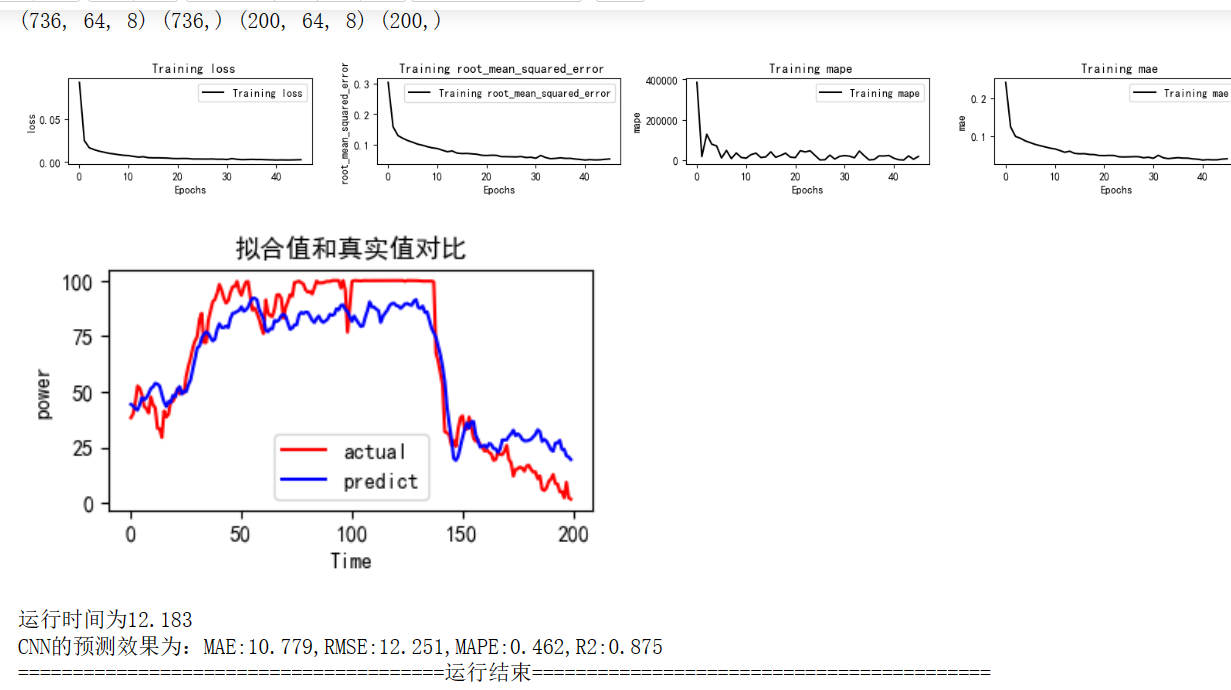
一维CNN
mode='CNN' set_my_seed() train_fuc(mode=mode,window_size=window_size,batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)
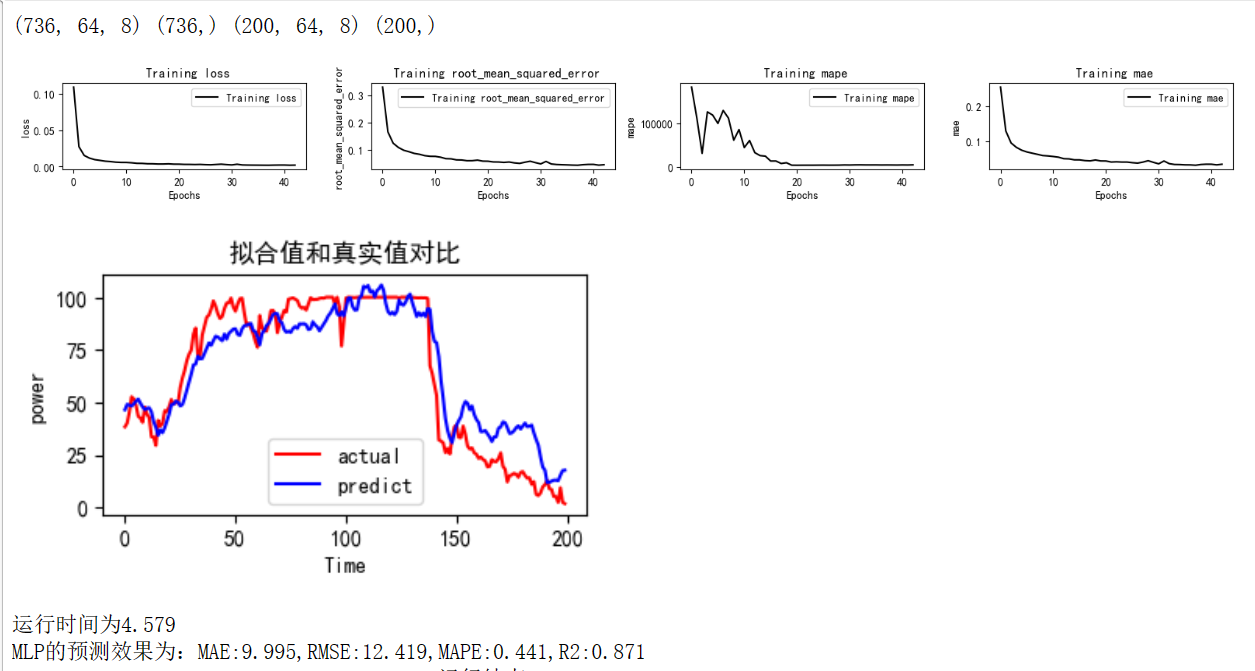
MLP
mode='MLP' set_my_seed() train_fuc(mode=mode,window_size=window_size,batch_size=batch_size,epochs=60,hidden_dim=hidden_dim)
评价指标
查看:
df_eval_all

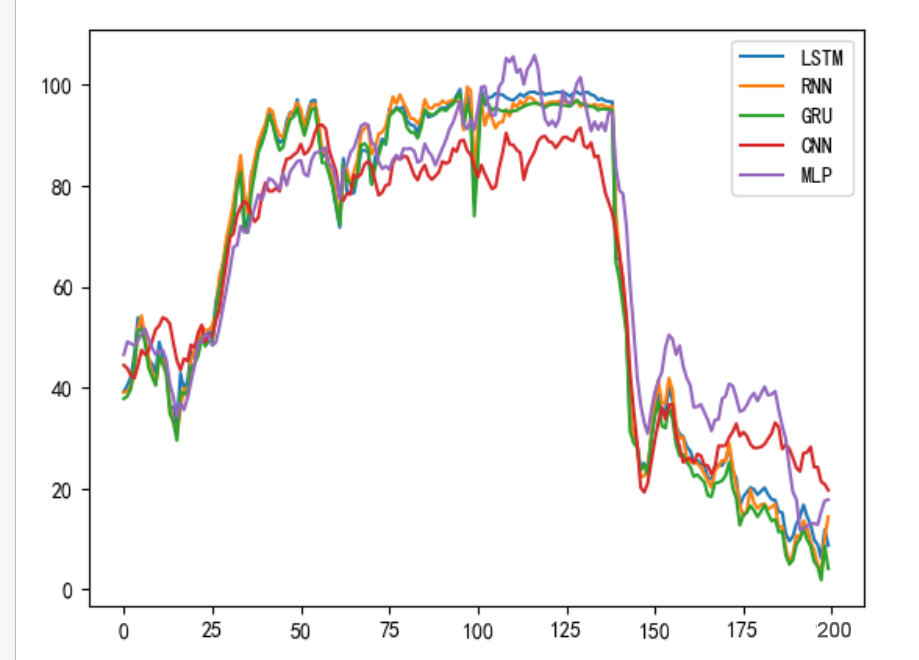
可以看到模型的预测效果都还不错,都有90%以上,GRU等循环神经网络效果很好,LSTM调了一下参数,效果是最好的。
预测结果
df_preds_all

然后可以用这个画图什么的: