
【Python数据分析案例】(十)——西雅图交通事故预测(不平衡样本处理)

网盘截屏


▶全部源码和数据,请点击“支付下载”获取!支付后无网盘链接,请联系客服QQ:3345172409或1919588043(微信同号)☺
导读
本次案例适合机器学习数据科学方向的同学。
交通事故是一个严重的公共安全问题,在全球范围内每年都有成千上万的人死于交通事故。随着交通运输的发展和城市化进程的加速,交通事故已成为制约城市发展和人民幸福的主要因素之一。因此,通过分析交通事故的原因和严重程度,以及开发有效的预测模型,可以有效预防交通事故的发生,并减少交通事故对人类社会的危害。
本研究的目标是通过机器学习模型预测交通事故的严重程度,以保护城市居民免受交通事故的严重伤害并防止交通碰撞。为了实现这一目标,我们将分析影响交通事故严重程度的各种因素,并建立一个准确、可靠的预测模型。
目前,人们通常依靠经验和统计数据来评估交通事故的严重程度。但是,这种方法的缺点是可能存在主观性和局限性,无法准确预测交通事故的发生和严重程度。相比之下,机器学习模型可以自动学习和优化模型,以最大程度地准确预测交通事故的严重程度。本研究旨在比较当前解决方案和我们提出的解决方案之间的优缺点,以证明机器学习模型在交通事故预测方面的优势。
最后,我们将通过分析西雅图市10年内的交通事故数据来提供支持我们研究的证据,我们的响应变量y是SEVERITYCODE(事故严重程度代码)。因为在一个交通事故中,事故严重程度是我们最关心的问题,也是我们希望能够预测的目标变量。其他列则可能作为预测变量x,帮助我们预测事故严重程度。本研究将为西雅图交通政府制定更有效的交通事故预防措施和政策提供科学依据。
导入包
#导入数据分析常用包 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline plt.rcParams['axes.unicode_minus'] = False #负号
数据探索
# 读取数据
data=pd.read_csv('Collisions.csv',na_values='Unknown')
#查看数据前三行
data.head(3)

#自动解析数据类型 data=data.infer_objects() #查看数据信息 data.info()
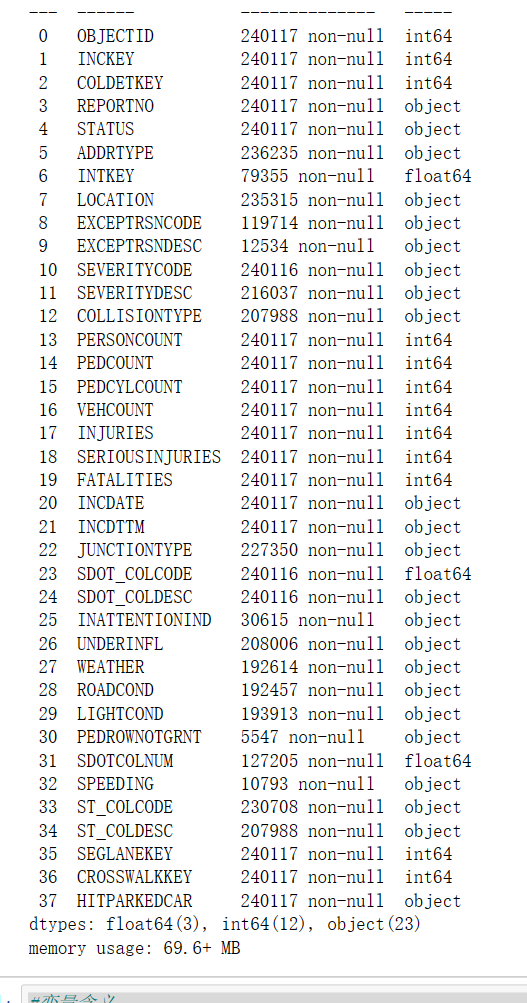
#变量含义
”’OBJECTID:事故对象的标识符
INCKEY:内部事故唯一键
COLDETKEY:采集数据的标识符
REPORTNO:事故报告号
STATUS:事故处理状态
ADDRTYPE:地址类型
INTKEY:十字路口标识符
LOCATION:事故位置
EXCEPTRSNCODE:例外原因代码
EXCEPTRSNDESC:例外原因描述
SEVERITYCODE:事故严重程度代码
SEVERITYDESC:事故严重程度描述
COLLISIONTYPE:碰撞类型
PERSONCOUNT:涉及的人数
PEDCOUNT:行人数量
PEDCYLCOUNT:自行车数量
VEHCOUNT:涉及的车辆数量
INJURIES:受伤人数
SERIOUSINJURIES:严重受伤人数
FATALITIES:死亡人数
INCDATE:事故发生日期
INCDTTM:事故发生日期和时间
JUNCTIONTYPE:交叉口类型
SDOT_COLCODE:SDOT收集的事故代码
SDOT_COLDESC:SDOT收集的事故描述
INATTENTIONIND:不注意标记
UNDERINFL:受到驾驶员的影响
WEATHER:天气状况
ROADCOND:道路条件
LIGHTCOND:光线条件
PEDROWNOTGRNT:行人未被授予权利
SDOTCOLNUM:SDOT收集的事故编号
SPEEDING:超速行驶
ST_COLCODE:州事故代码
ST_COLDESC:州事故描述
SEGLANEKEY:分段车道关键字
CROSSWALKKEY:人行横道关键字
HITPARKEDCAR:是否碰撞停放的车辆”’
#观察缺失值 import missingno as msno msno.matrix(data)

数据预处理
特征预处理
'''OBJECTID,INCKEY,COLDETKEY,REPORTNO''' #这四个变量是取值唯一的编号型变量,对于模型没有帮助,删除 data.drop(columns=['OBJECTID','INCKEY','COLDETKEY','REPORTNO'],inplace=True)
#若是有一行全为空值就删除
data.dropna(how='all',inplace=True)
#取值唯一的变量删除 (如果有一列的值全部一样,也就是取值唯一的特征变量就可以删除了,因为每个样本没啥区别,对模型就没啥用)
for col in data.columns: if len(data[col].value_counts())==1: print(col) data.drop(col,axis=1,inplace=True)

#缺失到一定比例就删除,缺失量达到一定程度就给他删了,缺失太多不如不要这个特征。我这里的比例是20%
miss_ratio=0.2 for col in data.columns: if data[col].isnull().sum()>data.shape[0]*miss_ratio: print(col) data.drop(col,axis=1,inplace=True)

总共38个变量,现在已经删除了11个了
然后需要对数据进一步细化处理,要把数据分为数值型和其他类型来看。
首先查看数值型数据
数值型变量预处理
#查看数值型数据,
pd.set_option('display.max_columns', 20)
data.select_dtypes(exclude=['object']).head()

做机器学习当然需要特征越分散越好,因为这样就可以在X上更加有区分度,从而更好的分类。
所以那些数据分布很集中的变量可以扔掉。
可以用方差,但是由于数据的口径大小不一致,方差不好对比,
这里我们采用异众比例来衡量数据的分散程度,若异众比例低于0.02就删除
#计算异众比例
variation_ratio_s=0.02
for col in data.select_dtypes(exclude=['object']).columns:
df_count=data[col].value_counts()
kind=df_count.index[0]
variation_ratio=1-(df_count.iloc[0]/len(data[col]))
if variation_ratio<variation_ratio_s:
print(f'{col} 最多的取值为{kind},异众比例为{round(variation_ratio,4)},太小了,没区分度需要删掉')
#data.drop(col,axis=1,inplace=True)

我们发现SERIOUSINJURIES,FATALITIES,SEGLANEKEY ,CROSSWALKKEY 四个变量的异众比例是很小的,大部分取值都是0。
但是SERIOUSINJURIES 严重受伤程度 和FATALITIES 死亡数量都是对于交通严重程度很多有的变量,我们选择保留他们。
而SEGLANEKEY和CROSSWALKKEY 是路段ID和人行横道ID,对于预测作用应该不大,选择删除。
##删除 SEGLANEKEY和CROSSWALKKEY data.drop(columns=['SEGLANEKEY','CROSSWALKKEY'],inplace=True)
object型变量预处理
查看非数值变量前三行
data.select_dtypes(include=[‘object’]).head(3)

‘LOCATION’,’SDOT_COLDESC’,’ST_COLCODE’,’ST_COLDESC’,
#这四个变量都是针对这个事件的具体描述,有的是文本类型,做不了特征变量,删除
‘SEVERITYDESC’,’STATUS’,’SDOT_COLCODE’
#这几个变量对于交通严重程度没有解释作用,也删除
data.drop(columns=[‘LOCATION’,’SDOT_COLDESC’,’ST_COLCODE’,’ST_COLDESC’,’SEVERITYDESC’,’STATUS’,’SDOT_COLCODE’],inplace=True)
填充缺失值
1.删除缺失值:对于一些缺失值的行比较少的变量可以直接删除缺失值的行样本。
可以看出我们的响应变量SEVERITYCODE存在缺失值,而且只有一个缺失值,删掉这个缺失值不会对数据整体造成太大的影响,
而且缺失值可能会对后续的建模和分析产生干扰和误差,因此在这种情况下,我们可以直接删除存在缺失值的行。
2.其他变量填充缺失值:
(1)对于类别变量(如ADDRTYPE, COLLISIONTYPE, JUNCTIONTYPE, UNDERINFL, WEATHER, ROADCOND, LIGHTCOND)可以使用众数进行填充。
# 删除缺失值 data.dropna(subset=['SEVERITYCODE'], inplace=True) # 类别变量填充众数 data['ADDRTYPE'].fillna(data['ADDRTYPE'].mode()[0], inplace=True) data['COLLISIONTYPE'].fillna(data['COLLISIONTYPE'].mode()[0], inplace=True) data['JUNCTIONTYPE'].fillna(data['JUNCTIONTYPE'].mode()[0], inplace=True) data['UNDERINFL'].fillna(data['UNDERINFL'].mode()[0], inplace=True) data['WEATHER'].fillna(data['WEATHER'].mode()[0], inplace=True) data['ROADCOND'].fillna(data['ROADCOND'].mode()[0], inplace=True) data['LIGHTCOND'].fillna(data['LIGHTCOND'].mode()[0], inplace=True)
特征工程
两个时间变量进行转化,变为时间的格式
data['INCDTTM'] = pd.to_datetime(data['INCDTTM']) data['INCDATE'] = pd.to_datetime(data['INCDATE'])
INCDTTM变量包含小时,更为详细,对INCDTTM这个变量里面提取时间特征就行,我们提取这个事故发生的年,月,小时。因为日可能没有明显的含义,而月份代表季节性,小时代表每天的交通事故发生的可能性最大的时刻,所以选择年,月,小时三个作为新特征
data['year']=data['INCDTTM'].dt.year data['month']=data['INCDTTM'].dt.year data['hour']=data['INCDTTM'].dt.hour
构建了新特征后,原来的特征不要的就删除
data.drop(columns=['INCDTTM','INCDATE'],inplace=True)
UNDERINFL中有重复含义变量,需要进行处理
#将0变为N,1变为Y
data['UNDERINFL']=data['UNDERINFL'].map({'N':'N','0':'N','Y':'Y','1':'Y'})
#查看处理完的数据信息
print(data.shape) data.info()

没有缺失值了。
#首先对训练集取出y y=data['SEVERITYCODE'] data.drop(['SEVERITYCODE'],axis=1,inplace=True)
##查看分类变量的每个变量分为几类
for col in data.select_dtypes(include=['object']).columns:
print(f"{col}变量有{len(data[col].unique())}类")

数据探索
数值型变量画图
#查看特征变量的箱线图分布
columns = data.select_dtypes(exclude=['object']).columns.tolist() # 列表头
dis_cols = 4 #一行几个
dis_rows = len(columns)
plt.figure(figsize=(4 * dis_cols, 4 * dis_rows),dpi=128)
for i in range(len(columns)):
plt.subplot(dis_rows,dis_cols,i+1)
sns.boxplot(data=data[columns[i]], orient="v",width=0.5)
plt.xlabel(columns[i],fontsize = 20)
plt.tight_layout()
#plt.savefig('特征变量箱线图',formate='png',dpi=500)
plt.show()
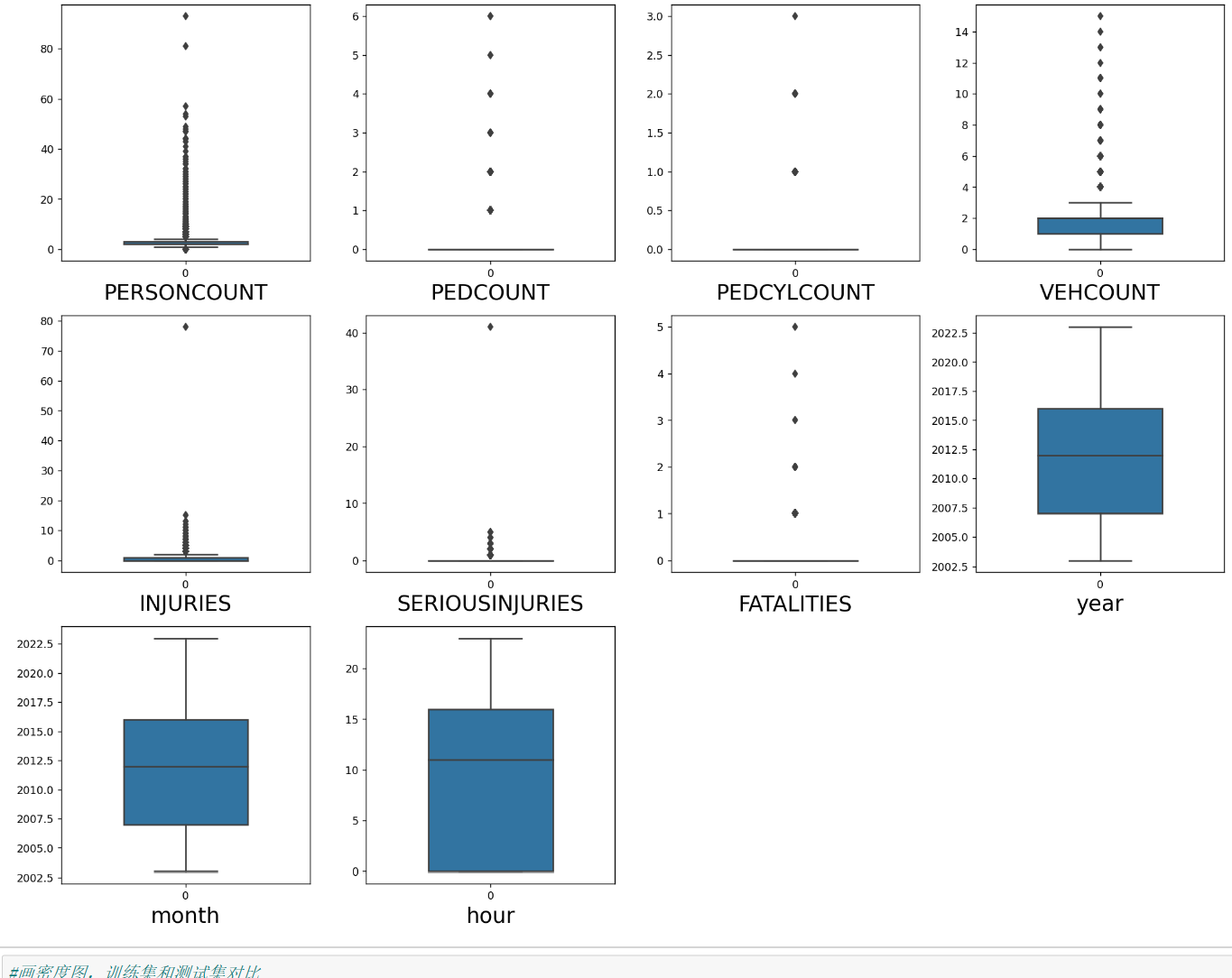
#画密度图,训练集和测试集对比
dis_cols = 4 #一行几个
dis_rows = len(columns)
plt.figure(figsize=(4 * dis_cols, 4 * dis_rows),dpi=128)
for i in range(len(columns)):
ax = plt.subplot(dis_rows, dis_cols, i+1)
ax = sns.kdeplot(data[columns[i]], color="Red" ,fill=True)
ax.set_xlabel(columns[i],fontsize = 20)
ax.set_ylabel("Frequency",fontsize = 18)
plt.tight_layout()
#plt.savefig('训练测试特征变量核密度图',formate='png',dpi=500)
plt.show()

分类型变量画图
#查看特征变量的箱线图分布
columns = data.select_dtypes(include=['object']).columns.tolist() # 列表头
dis_cols = 3 #一行几个
dis_rows = len(columns)
plt.figure(figsize=(5 * dis_cols, 5 * dis_rows),dpi=128)
for i in range(len(columns)):
plt.subplot(dis_rows,dis_cols,i+1)
sns.barplot(x=data[columns[i]].value_counts().index, y=data[columns[i]].value_counts().values)
#sns.barplot(data=data[columns[i]].value_counts(), orient="v",width=0.5)
plt.xlabel(columns[i],fontsize = 15)
plt.xticks(rotation=45)
plt.tight_layout()
#plt.savefig('特征变量箱线图',formate='png',dpi=500)
plt.show()
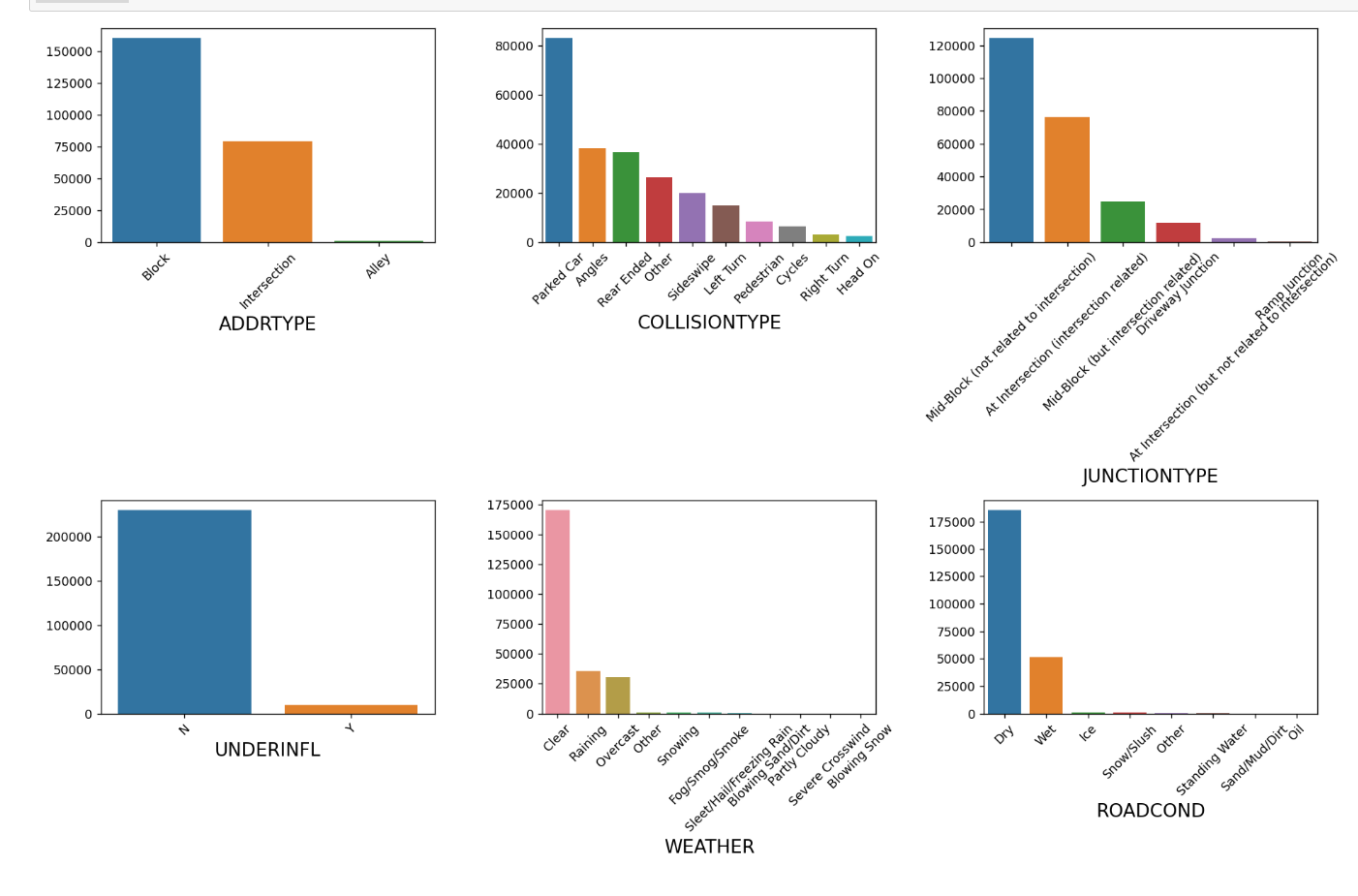
相关性分析
#画出数值型变量之间的相关性 corr = plt.subplots(figsize = (18,16),dpi=128) corr= sns.heatmap(data.corr(method='spearman'),annot=True,square=True)

分类变量进行独立热编码
#很多x都是文本型分类变量,所以要进行的独立热编码处理
data=pd.get_dummies(data) data.shape

查看响应变量的分布
y.value_counts()

可视化
# 查看y的分布
#分类问题
plt.figure(figsize=(8,3),dpi=128)
plt.subplot(1,2,1)
y.value_counts().plot.bar(title='Response variable histogram graph')
plt.subplot(1,2,2)
y.value_counts().plot.pie(title='Response Variable Pie Chart')
#plt.savefig('响应变量.png')
plt.tight_layout()
plt.show()
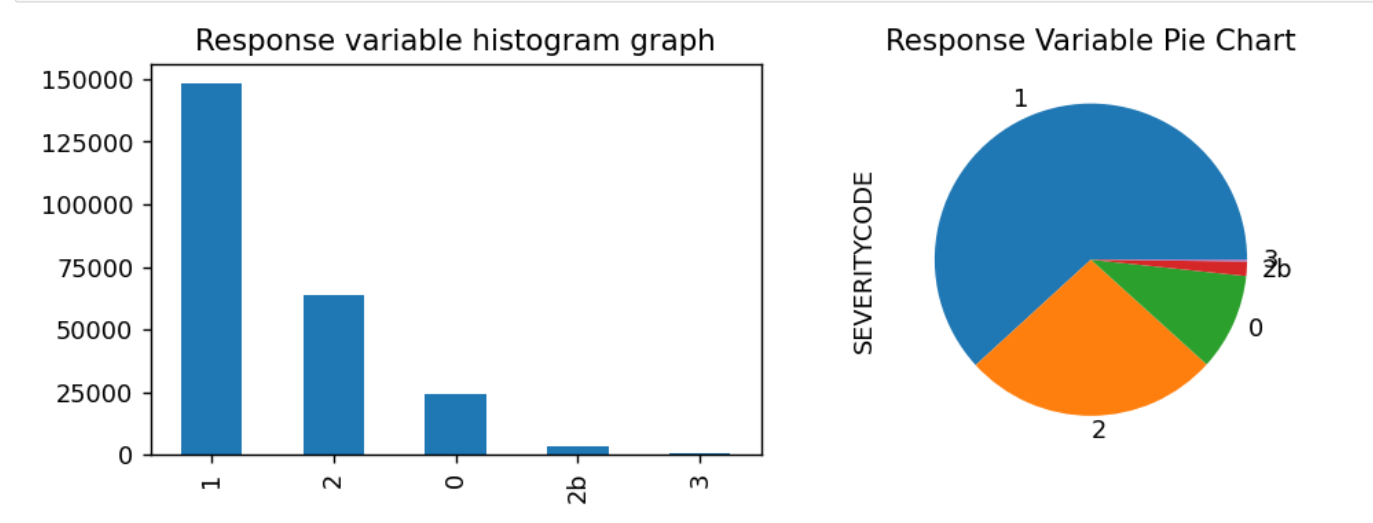
响应变量数据分布存在极度的不平衡情况,我们将0,1,2,2b四组情况映射为0, 3(表示交通事故很严重)映射为1,表示是一个二分类问题
y=y.map({'0':0,'1':0,'2':0,'2b':0,'3':1})
y.value_counts()

下面对y进行类别平衡处理
在处理极度不平衡的分类样本时,可以考虑以下几种方法: 欠采样(Undersampling):从多数类别中随机选择一部分样本,使得多数类别的样本数量与少数类别的样本数量相近。这种方法的优点是简单快捷,但可能会丢失一些有用信息。
过采样(Oversampling):从少数类别中随机复制一些样本,使得少数类别的样本数量与多数类别的样本数量相近。这种方法的优点是可以充分利用数据集,但可能会导致过拟合。
SMOTE(Synthetic Minority Over-sampling Technique)算法:是一种常用的过采样方法,它通过对少数类别样本进行插值生成新的样本来扩充数据集。这种方法可以有效地避免过拟合问题。
混合采样(Mixed Sampling):结合欠采样和过采样的优点,既可以减少数据量,又可以充分利用数据集。可以先进行欠采样,然后再对欠采样后的数据进行过采样。
我们首先对样本少的进行上采样
from imblearn.over_sampling import RandomOverSampler
os=RandomOverSampler(sampling_strategy=0.0025)
X_train_ns,y_train_ns=os.fit_resample(data,y)
print("The number of classes before fit {}".format(y.value_counts().to_dict()))
print("The number of classes after fit {}".format(y_train_ns.value_counts().to_dict()))

将y为1的样本增加到599个
再对样本多的进行下采样,比例为0.2,即0类数量8成,1类数量2成。虽然也不平衡,但是比刚刚那个好多了。。也能训练了。
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(sampling_strategy=0.2)
X_resampled, y_resampled = rus.fit_resample(X_train_ns, y_train_ns)
X_train_ns2,y_train_ns2=rus.fit_resample(X_train_ns,y_train_ns)
print("The number of classes before fit {}".format(y_train_ns.value_counts().to_dict()))
print("The number of classes after fit {}".format(y_train_ns2.value_counts().to_dict()))
查看现在的数据形状

print(X_train_ns2.shape,y_train_ns2.shape)
![]()
共3594个样本,其中0类有2995条,1类有599条,x特征变量的个数有57个
算法实现
#划分训练集和测试集,查看他们的形状 from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X_train_ns2,y_train_ns2,stratify=y_train_ns2,test_size=0.2,random_state=0) print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)

#数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_s = scaler.transform(X_train)
X_test_s = scaler.transform(X_test)
print('训练数据形状:')
print(X_train_s.shape,y_train.shape)
print('测试数据形状:')
print(X_test_s.shape,y_test.shape)

上述代码是先划分训练集和测试集,测试集的比例为20%,随机数种子为0。然后进行数据的标准化, 打印查看训练集数据,测试集数据的形状。 可以看到我们有训练集4598,测试集1150,特征变量有74个。
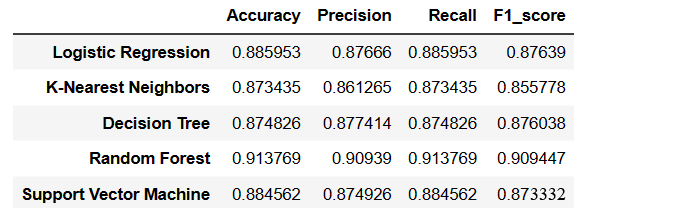
#采用五种模型,对比验证集精度
from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVC #逻辑回归 model1 = LogisticRegression(C=1e10,max_iter=10000) #K近邻 model2 = KNeighborsClassifier(n_neighbors=10) #决策树 model3 = DecisionTreeClassifier(random_state=77) #随机森林 model4= RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=10) #支持向量机 model5 = SVC(kernel="rbf", random_state=77) model_list=[model1,model2,model3,model4,model5] model_name=['Logistic Regression', 'K-Nearest Neighbors', 'Decision Tree', 'Random Forest','Support Vector Machine']
评价标准
本文是一个分类问题,采用四个分类问题常用而且可靠的评价指标,准确率、精确度、召回率和F1值对模型进行全面的评价。四个指标的计算公式如下

计算所有评价指标,定义评估函数
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_score
from sklearn.model_selection import KFold
def evaluation(y_test, y_predict):
accuracy=classification_report(y_test, y_predict,output_dict=True)['accuracy']
s=classification_report(y_test, y_predict,output_dict=True)['weighted avg']
precision=s['precision']
recall=s['recall']
f1_score=s['f1-score']
#kappa=cohen_kappa_score(y_test, y_predict)
return accuracy,precision,recall,f1_score #, kappa
def evaluation2(lis):
array=np.array(lis)
return array.mean() , array.std()
df_eval=pd.DataFrame(columns=['Accuracy','Precision','Recall','F1_score'])
for i in range(5):
model_C=model_list[i]
name=model_name[i]
print(f'{name}模型拟合完成')
model_C.fit(X_train_s, y_train)
pred=model_C.predict(X_test_s)
s=classification_report(y_test, pred)
s=evaluation(y_test,pred)
df_eval.loc[name,:]=list(s)

df_eval
bar_width = 0.4
colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan']
fig, ax = plt.subplots(2,2,figsize=(10,8),dpi=128)
for i,col in enumerate(df_eval.columns):
n=int(str('22')+str(i+1))
plt.subplot(n)
df_col=df_eval[col]
m =np.arange(len(df_col))
plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)
#plt.xlabel('Methods',fontsize=12)
names=df_col.index
plt.xticks(range(len(df_col)),names,fontsize=10)
plt.xticks(rotation=40)
plt.ylabel(col,fontsize=14)
plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()
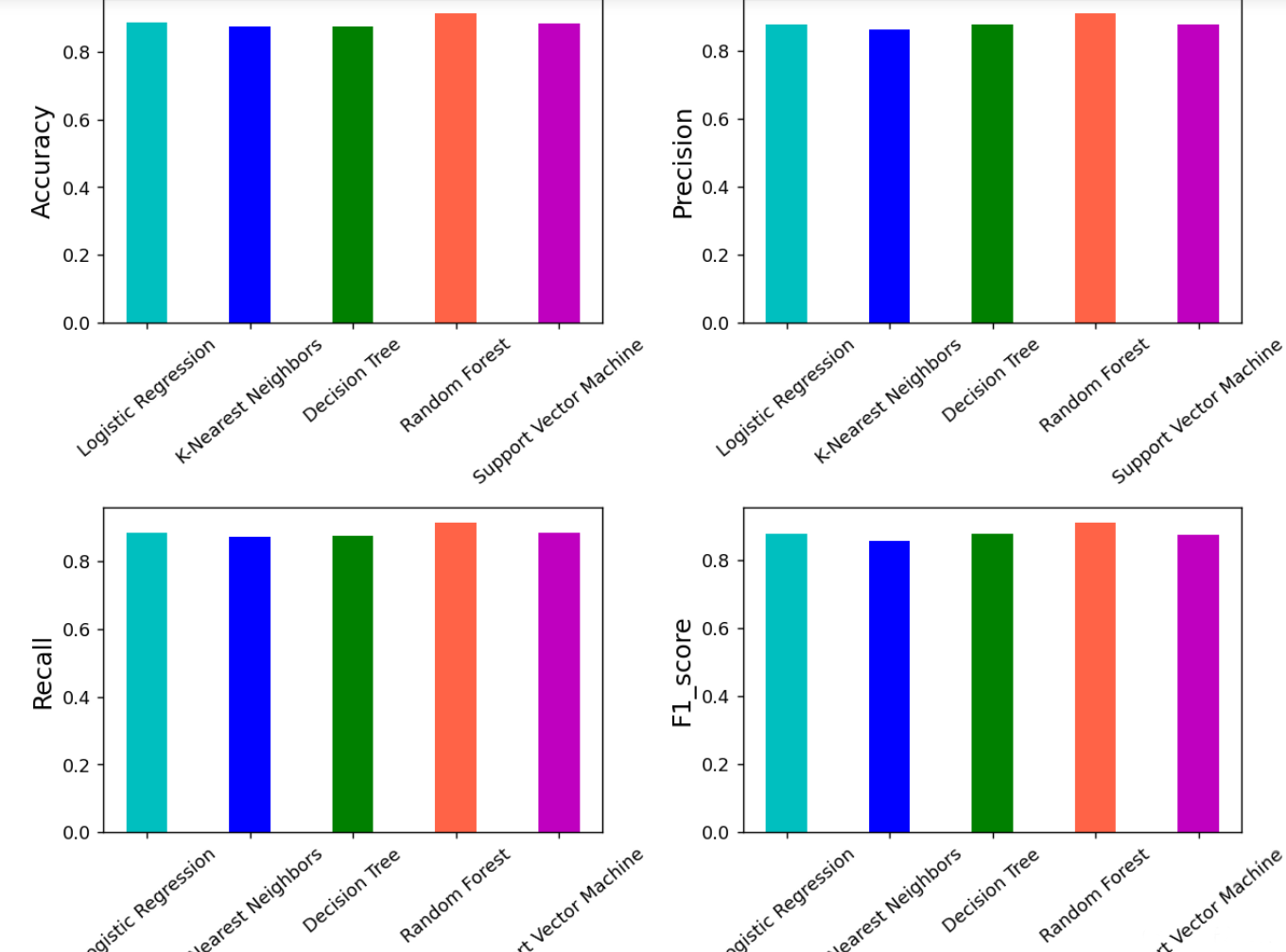
可以看到上面随机森林模型效果最好
下面对随机森林模型进一步进行超参数搜索
#利用K折交叉验证搜索最优超参数 from sklearn.model_selection import KFold, StratifiedKFold from sklearn.model_selection import GridSearchCV,RandomizedSearchCV
管道流,网格化搜索
from sklearn.pipeline import Pipeline
steps = [
('standardize', StandardScaler()),
('model',RandomForestClassifier(max_features='sqrt',random_state=10) ) ]
RF_pipe = Pipeline( steps = steps )
param_distributions = {'model__max_depth': range(2, 9),
'model__n_estimators': [250,500,750,1000,1500,2000]}
model= GridSearchCV( RF_pipe, param_distributions, n_jobs = 6, cv = KFold(n_splits=3, shuffle=True, random_state=0) )
查看这个管道里面的参数
RF_pipe.get_params()['model'].get_params().keys()

拟合模型
model.fit(X_train,y_train)

#查看模型最好的参数和准确率
print(f" best param: {model.best_params_},accuary:{model.best_score_}" )

#将最好的参数赋值给模型
model = model.best_estimator_
pred=model.predict(X_test_s)
s=evaluation(y_test,pred)
print(f'Acc: {s[0]}, Prec: {s[1]}, Recall: {s[2]}, F1:{s[3]}')

#准确率、精确度、召回率和F1值
RF_s=evaluation(model.predict(data),y) RF_s
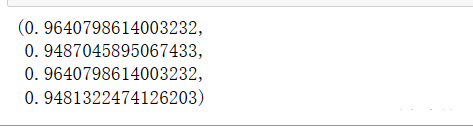
结论
模型的比较等等,在这个分类问题上,随机森林效果最好,其次是支持向量机和逻辑回归
本案例的局限性在于y取值为1的数据样本量太少,上采样多了可能会导致模型过拟合等等
变量重要性
#使用所有数据训练
model=RandomForestClassifier(max_depth= 8,n_estimators=2000,max_features='sqrt',random_state=10) #使用前面的最优参数
model.fit(np.array(data),y)
pred=model.predict(np.array(data))
s=evaluation(y,pred)
print(f'Acc: {s[0]}, Prec: {s[1]}, Recall: {s[2]}, F1:{s[3]}')

n=10
sorted_index = model.feature_importances_.argsort()[::-1][:n]
mfs=model.feature_importances_[sorted_index][:n]
plt.figure(figsize=(5,4),dpi=128)
sns.barplot(y=np.array(range(len(mfs))),x=mfs,orient='h')
plt.yticks(np.arange(data.shape[1])[:n], data.columns[sorted_index][:n])
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('LGBM')
plt.show()
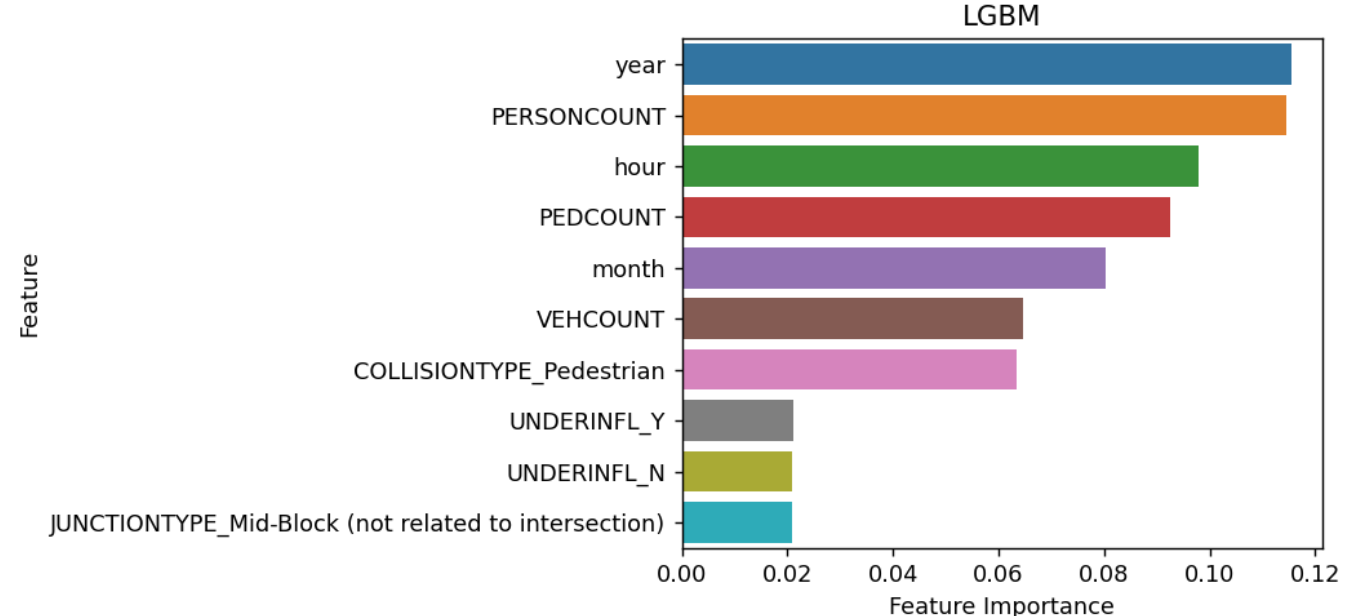
可以看到,PEDCOUNT,COLLISIONTYPE_Pedesttain等变量对于响应变量y的影响程度高,说明这个几个变量对交通事故有显著性影响
应该控制这几个变量,来减少交通事故的严重程度












