SpiderFlow平台v0.3.0初次使用并爬取薄荷网的热量和减法功效

spider-flow 作为web爬虫他可以简单的说是新一代的爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫。
也就是说我们不用在刻意的为了一些数据就去学一下语言如python,我们只要画个流程图配套的使用它的api就可以简单的快速爬取你想要的数据了。
我这先摘抄一下他在码云上的readm.md,等会儿再来详细说明一个我使用它平台爬取数据的案例,当然你要先看他提供的使用说明也就是api啦 https://www.spiderflow.org,看完再进入他的演示网站 http://demo.spiderflow.org/ 那里有很多的例子不过有很多都是别人测试的甚至有些就一个起步图标而已,之所以写这篇博客也就是记录一下我初学的结果啦。
spider-flow
【声明】 请勿将spider-flow应用到任何可能会违反法律规定和道德约束的工作中,请友善使用spider-flow,遵守蜘蛛协议,不要将spider-flow用于任何非法用途。如您选择使用spider-flow即代表您遵守此协议,作者不承担任何由于您违反此协议带来任何的法律风险和损失,一切后果由您承担。
介绍
新一代爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫。
QQ交流群:641108104

项目结构
spider-flow ├── spider-flow-api -- 插件开发的依赖 ├── spider-flow-core -- 核心包 ├── spider-flow-web -- web界面
特性
- 支持css选择器、正则提取
- 支持JSON/XML格式
- 支持Xpath/JsonPath提取
- 支持多数据源、SQL select/insert/update/delete
- 支持爬取JS动态渲染的页面
- 支持代理
- 支持二进制格式
- 支持保存/读取文件(csv、xls、jpg等)
- 常用字符串、日期、文件、加解密等函数
- 支持流程嵌套
- 支持插件扩展(自定义执行器,自定义函数)
- 任务监控
- 支持HTTP接口
插件列表
- Selenium插件
- Redis插件
- OSS插件
- Mongodb插件
- Hbase插件
- IP代理池插件
- OCR识别插件
- 电子邮箱插件
项目部分截图

spider-flow 搭建运行
spider-flow 是java开发的根据他的项目结构我很容易的就用idea快速的下载项目并搭建和运行起来
码云地址:https://gitee.com/jmxd/spider-flow.git
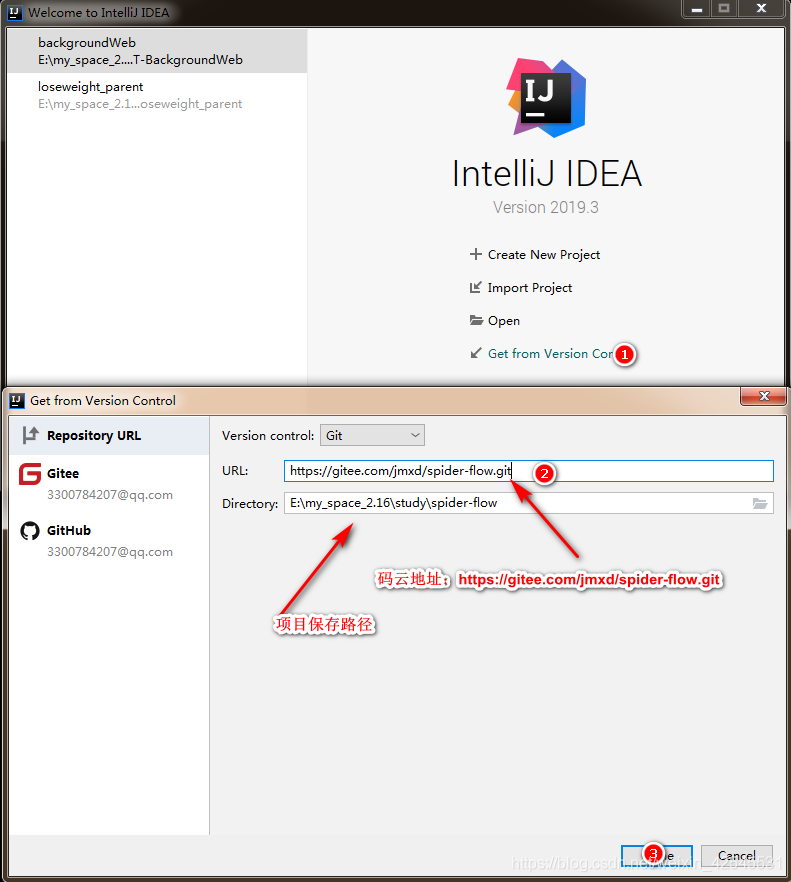
点击Clone后再用idea打开
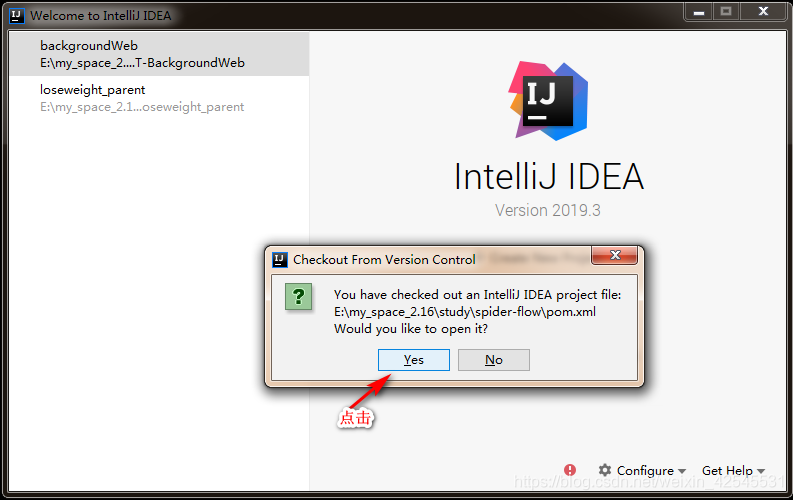

这样他的项目我们就用idea下载好了,接下来我们用一下他给的数据库sql文件生成一下表这里我用的是navcat,当然你也可以用我给的SQL文件,这里有我目前学过后保存的相关案例项目运行后就会在爬虫列表里显示出来
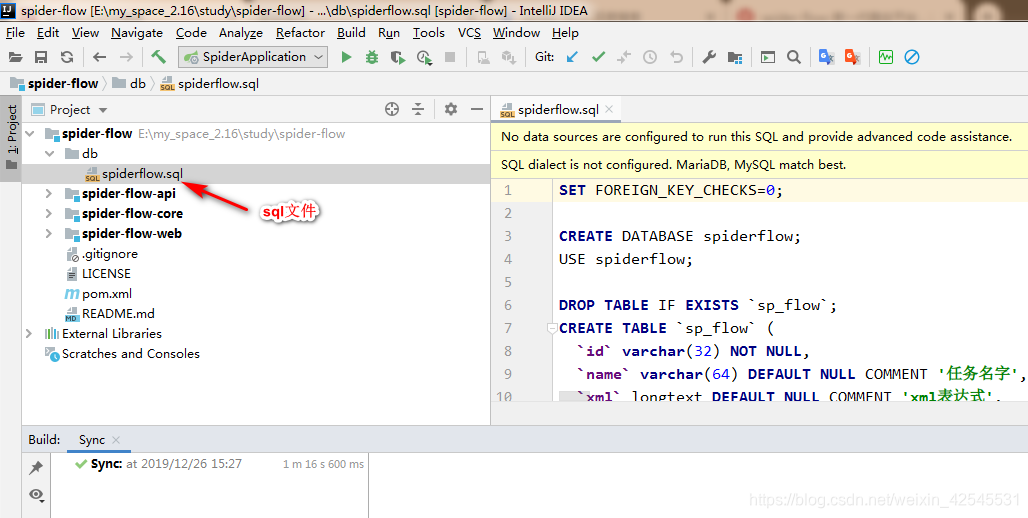
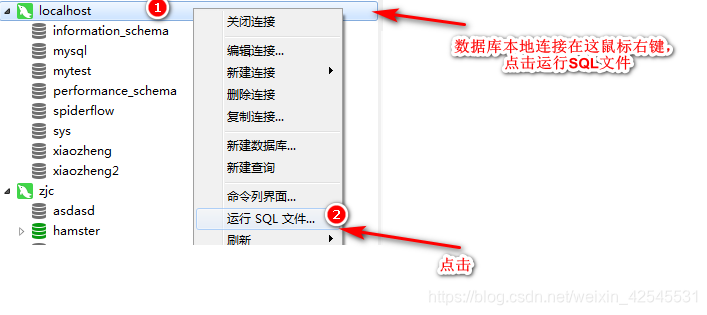
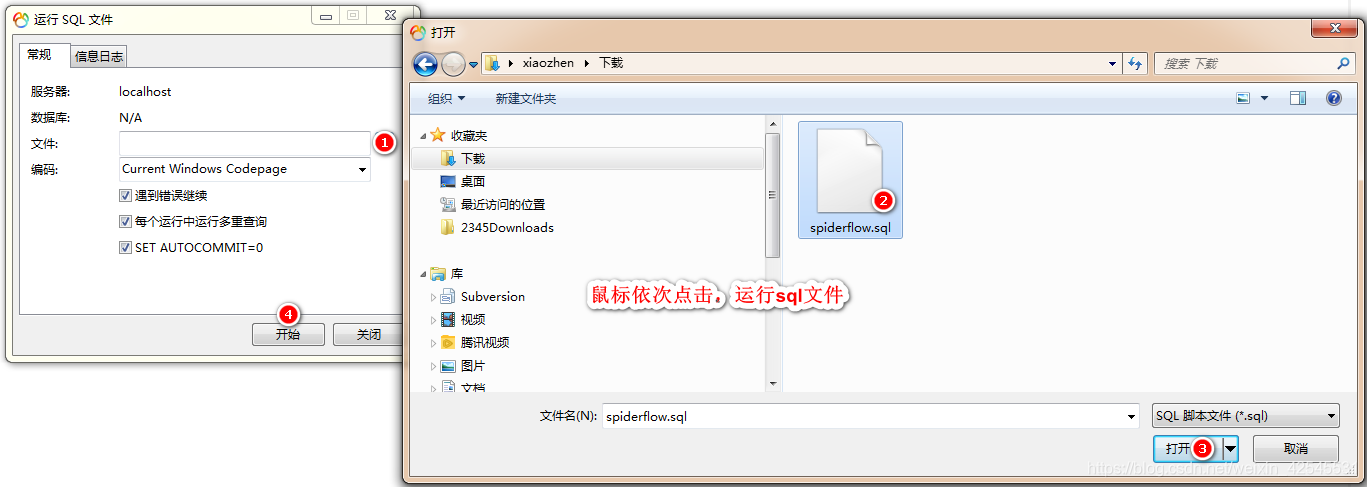
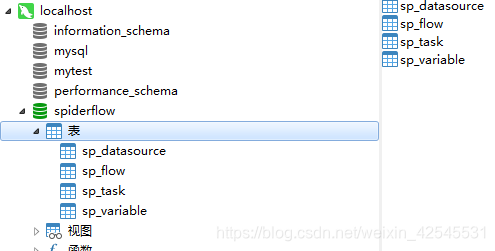
最后生成数据库和表
修改下他的web程序启动配置 application.properties

好了运行一下项目并访问一下
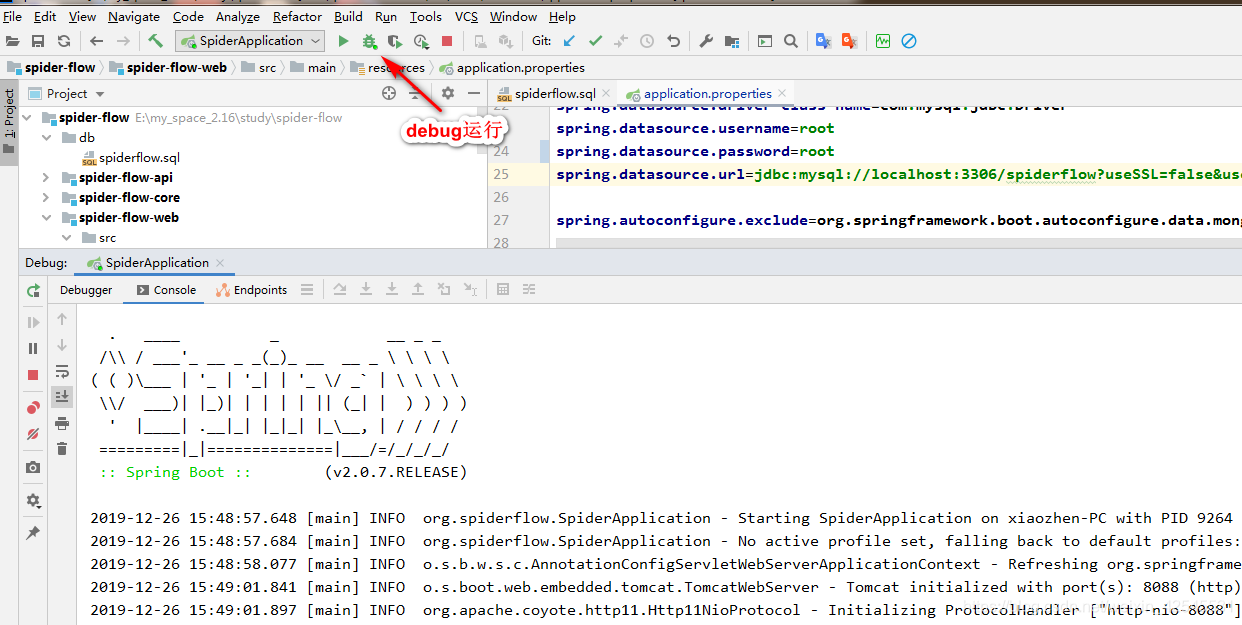
这里的案例我就不说了就用我看过他的api后自己敲得案例来说一下
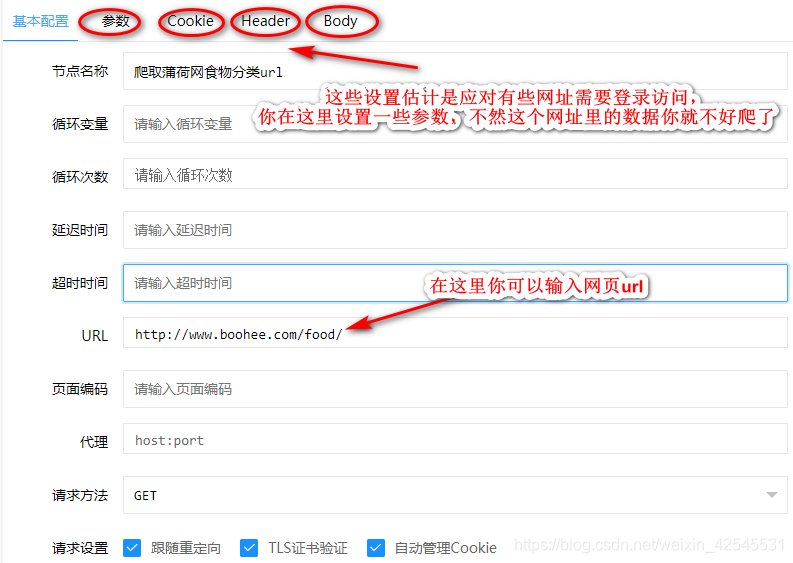
我这个案例就是爬取薄荷网站所有食物的热量和减肥功效,数据也不是太多就1581kb吧
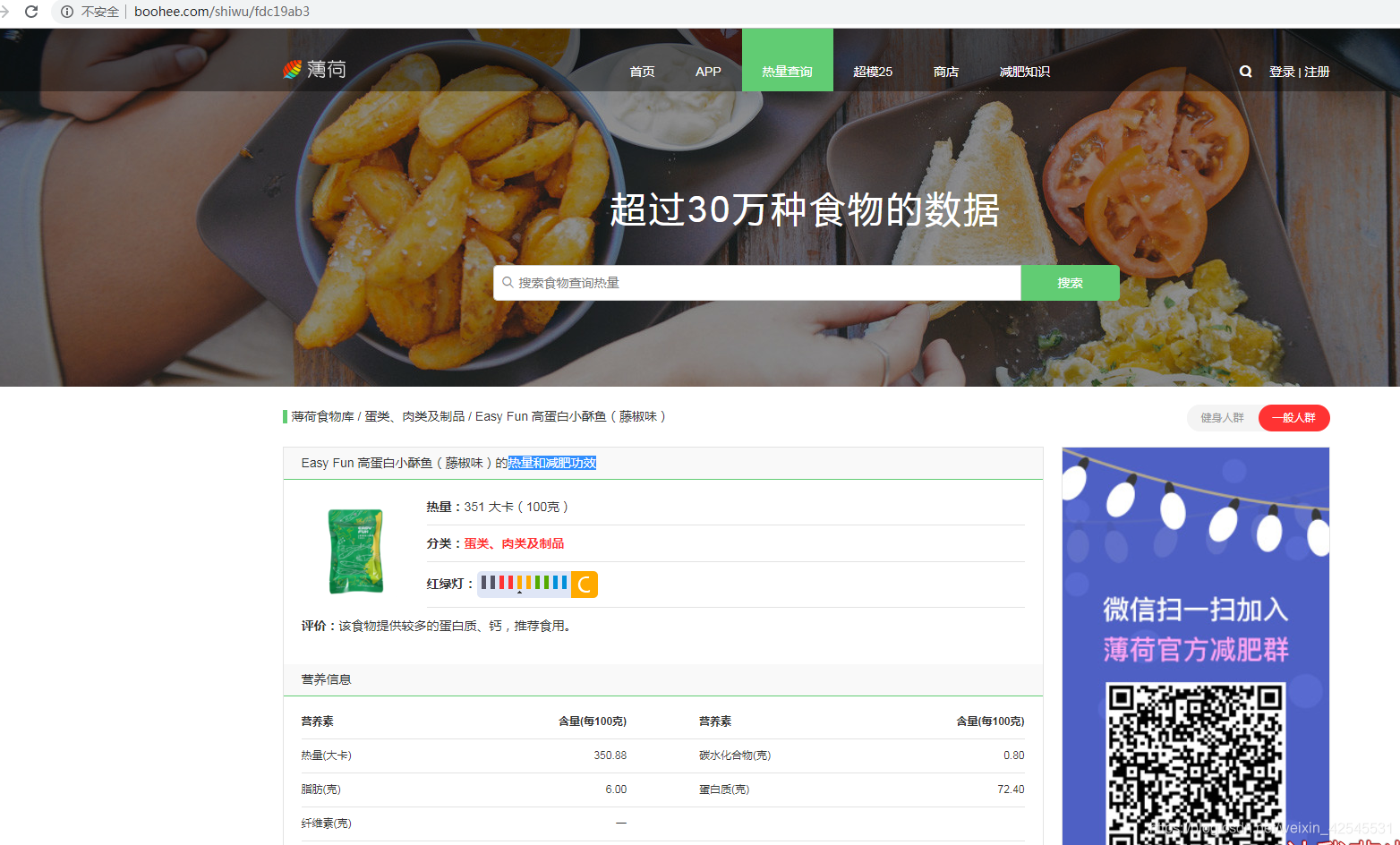
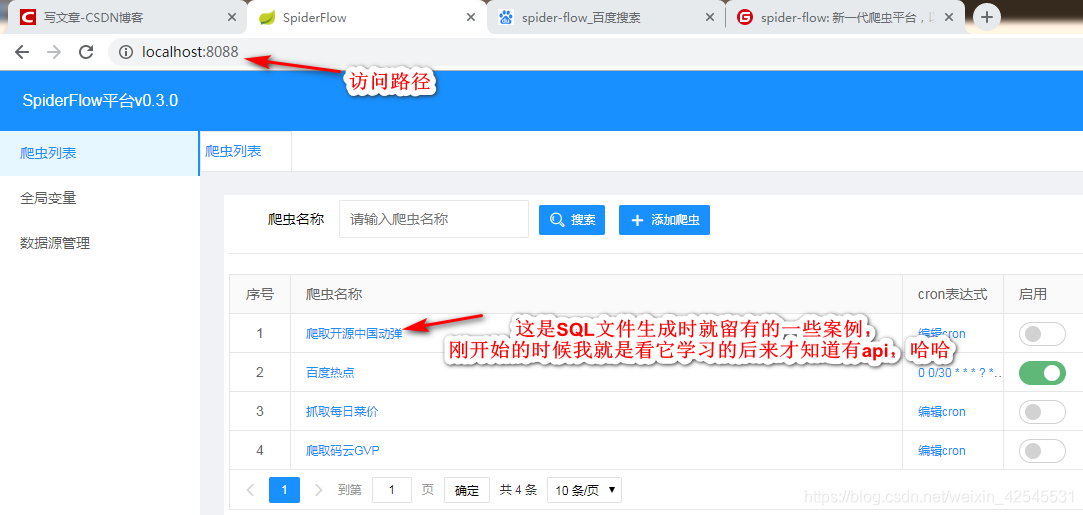
如果你运行SQL文件是用我给你的SQL文件那你可以在爬虫列表里看到我给的爬取薄荷网的热量和减法功效的案例点击进去如图
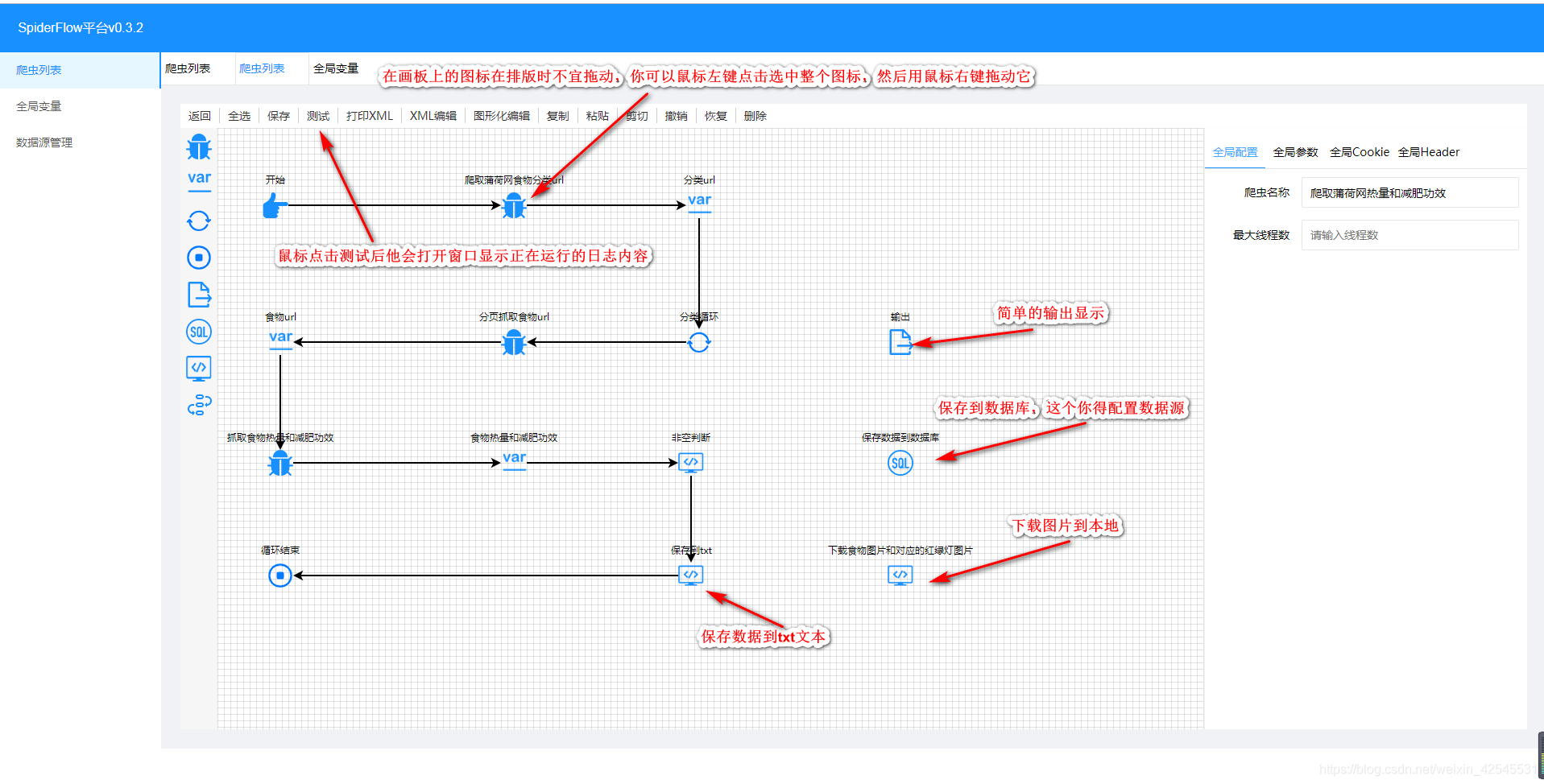
这张图最后有三种结果,你可以全部用箭头选中,也可以选一个
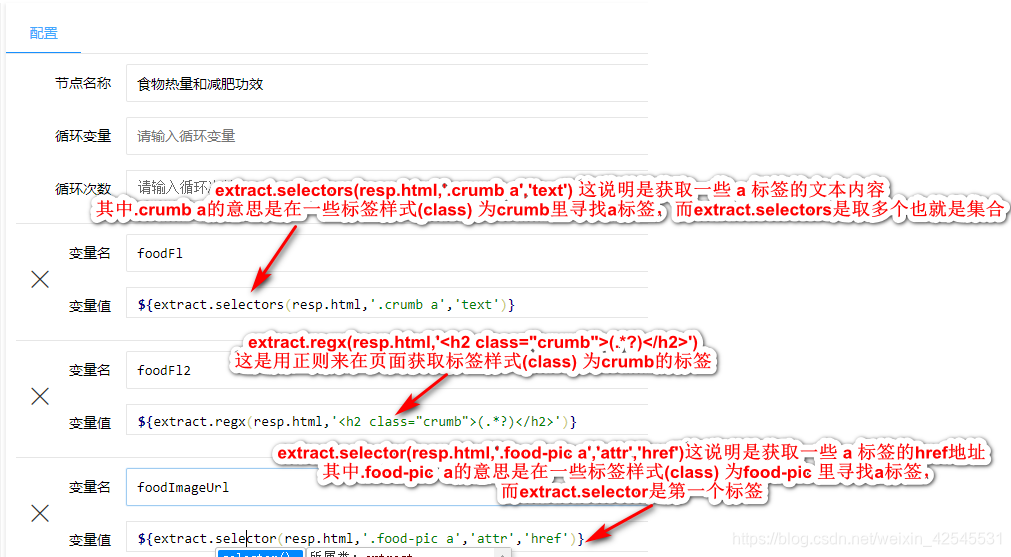
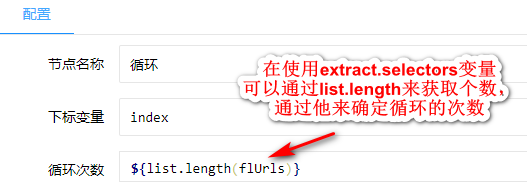
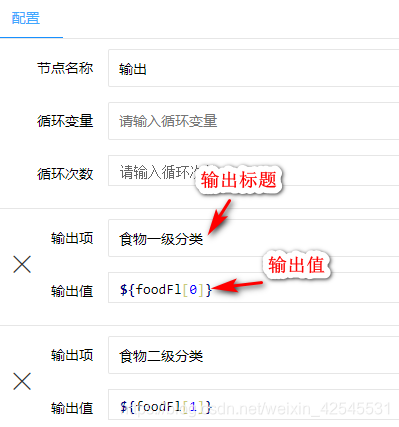
最后我用我的案例来说明一下其中的语句和使用方法
![]()
![]()
![]()
![]()
还没怎么使用过这个图标
![]()
![]()
使用这个图标你要先去添加一下数据源
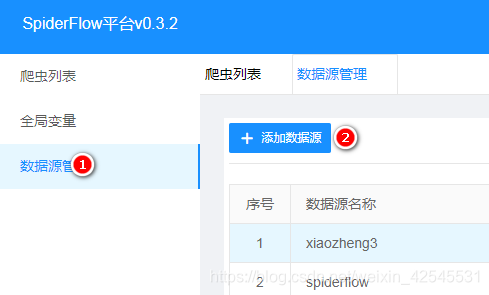
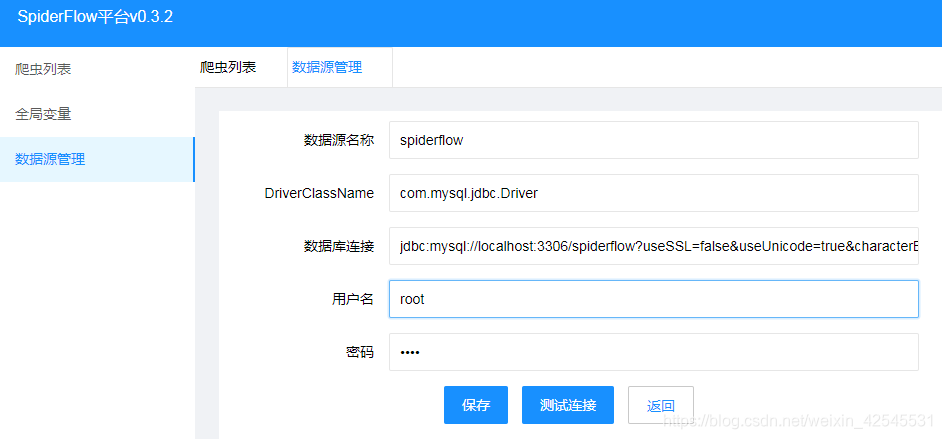
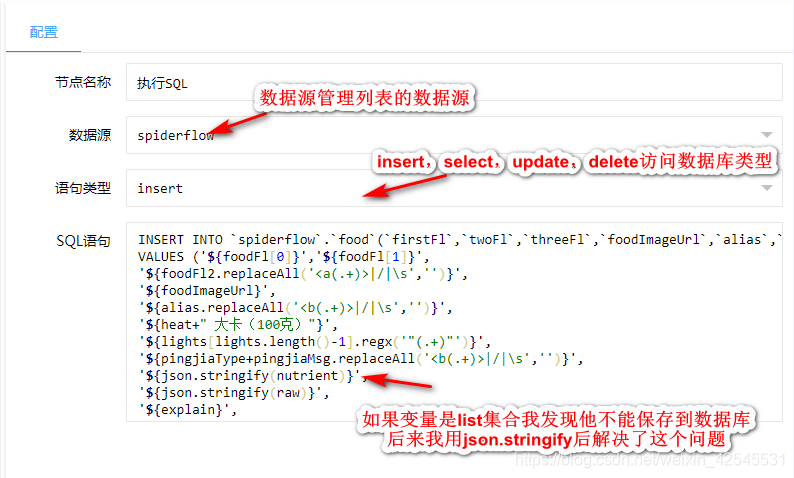
![]()
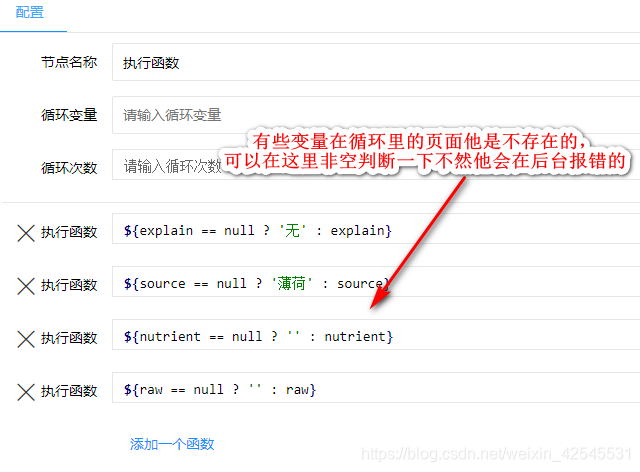
![]()
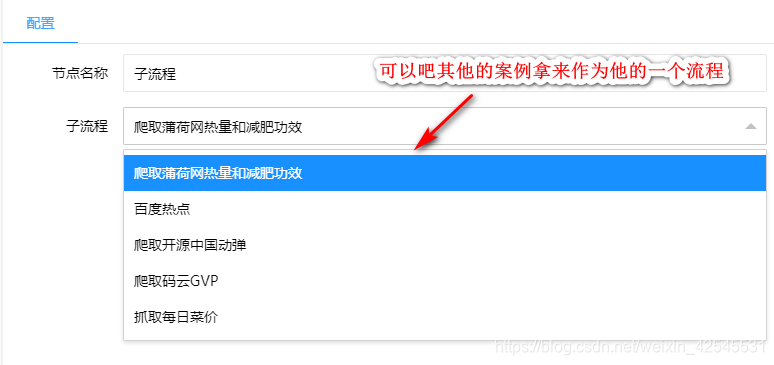
使用和图标介绍也就说道这里了,更多的请参考他的api,也希望他们提供的api和案例多一些毕竟好用但是不好学啊,就比如我现在还不知道怎么把数据保存到.xls表格太失败了我。
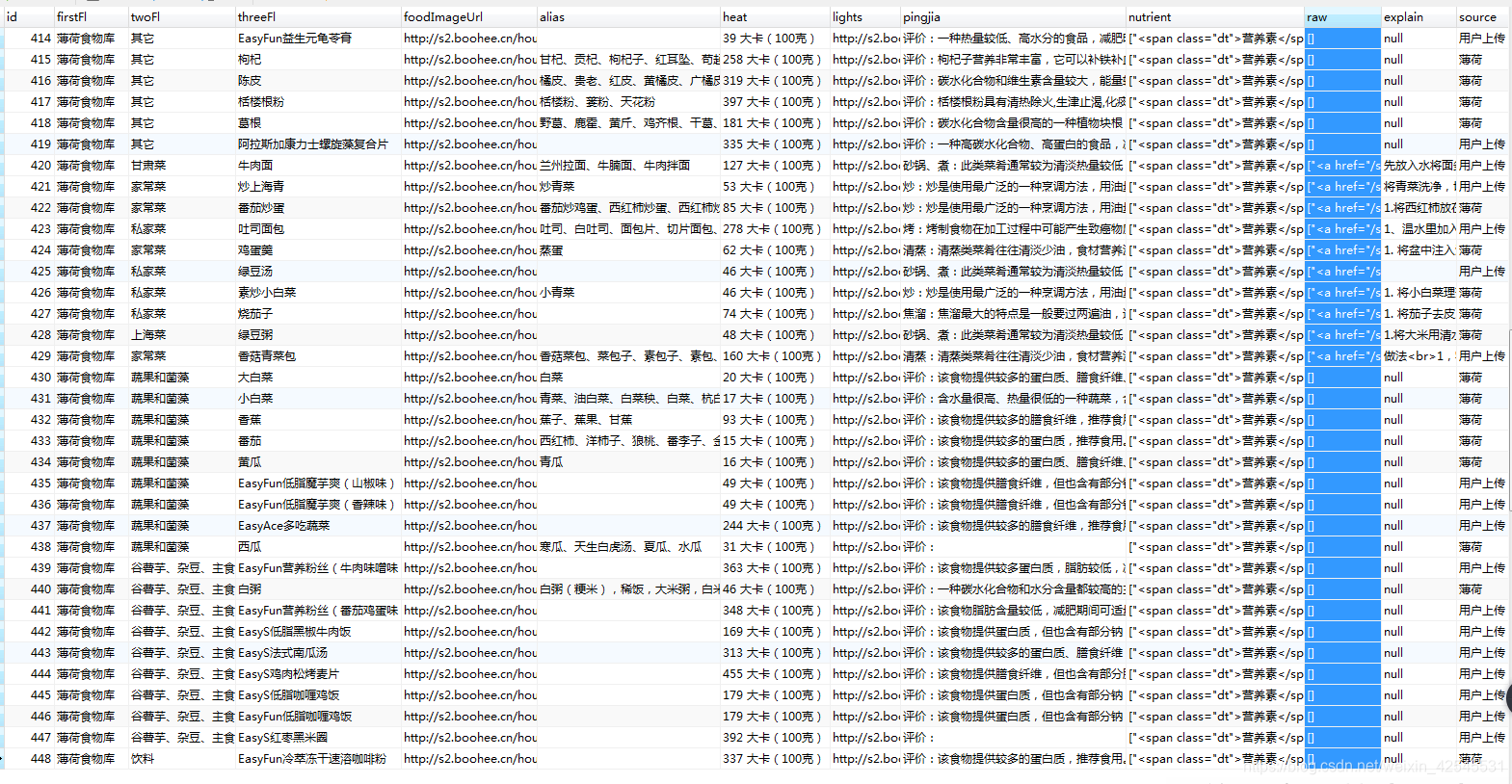
下面是我成功运行后保存的结果:
保存到数据库
保存到txt: